
본 내용을 들어가기에 앞서 아래 첨부된 자료들은 당근 DB팀에서 함께 고생하며 준비한 자료임을 밝힌다.
—
오늘은 작년(2023년 9월)에 AWS DNB DBA DAY에서 소프트웨어 엔지니어 및 데이터베이스 관리자를 대상으로 MySQL 8.0 캐릭터 셋(문자 집합)과 콜레이션에 대해서 발표한 내용을 공유해보려고 한다.
그 때 행사 담당자분이 AWS Database Blog에 내용을 정리해서 올려준다고 했는데 뭔가 흐지부지 된 느낌이다. 그래서 내용도 복습할겸 내가 정리하는 걸로..
발표 당시보다 내용을 좀 더 보강했기 때문에 신선한 내용도 있을 것이다.
(물론 그 때 발표를 들었던 사람에 한해)
그럼 이야기를 시작해보겠다.
- MySQL Character Set & Collation 개요
- UTF (Unicode Transformation Format)
- Chracter Set(UTF8)
- Collation
- Examples of Collation Comparison
- Collation 동작 방식
- 결론
MySQL Character Set & Collation 개요
MySQL 8.0의 캐릭터 셋은 크게 Simple character set과 Complex character set으로 나눌 수 있다. Simple한 캐릭터 셋은 Complex한 캐릭터 셋에 비해서 비교적 문자 분류 규칙이 단순하고 문자 수도 많지 않아서 <문자 집합>.xml(sql/share/charsets) 파일에 맵 형식으로 문자 하나하나가 정의되어 있는 캐릭터 셋이다.
그리고 complex한 캐릭터 셋은 문자 분류 규칙이 복잡하고, 복잡한 만큼 ctype_<문자 집합>.cc (/strings)파일에 각 문자 집합에 대한 규칙들이 프로그래밍 되어 있다. /strings 소스 경로에 가보면 내가 무슨 말을 하는지 알 것이다(공식 문서상에는 ctype_<문자 집합>.c 파일에 구현되어 있다고 설명하고 있지만 cpp 확장자가 맞다).
Simple character set은 xml 파일에 정의되어 있기 때문에 따로 컴파일을 하지 않아도 되고 필요할 때마다 xml 파일에서 참조되는 캐릭터 셋이다. Complex character set은 문자 분류 규칙들이 소스 파일에 복잡하게 프로그래밍 되어 있기 때문에 컴파일을 해야되는 캐릭터 셋이다.

Complex하고 Simple하다는게 어떤 의미인지 확 와닿지 않을 수도 있는데, 아래 테스트 결과를 보면 어떤 의미인지 대충 이해될 것이다. 너무 깊게 볼 필요없이 문자열 비교 규칙이 복잡한 캐릭터 셋일 수록 문자열을 비교 및 정렬하는 시간이 오래걸린다 정도로 이해하고 넘어가면 될 것 같다.

MySQL 서버의 캐릭터 셋 관리 구조는 이정도로 이야기하고, 이제 본격적으로 MySQL 서버의 캐릭터 셋에 대한 내용을 이야기해볼텐데, 정말 많은 캐릭터 셋이 존재하지만, 이번 내용에서는 MySQL 8.0의 기본 문자 집합인 utf에 대해서 좀 더 이야기를 해보도록 하겠다.
UTF
(Unicode Transformation Format)
MySQL 서버의 문자 집합을 설명하기 전에 UTF가 무엇인지에 대해서 먼저 알고 가면 좋을 것 같아서 살짝 설명을 해보려고 한다. 물론 잘 알고 있는 내용이라면 넘어가도 좋다.
UTF는 Unicode Transformation Format의 약자로, 유니코드 변환 포맷을 의미한다. 간단하게는 유니코드 문자 집합을 인코딩 하는 방법을 정의한 것이라고 보면 된다. (위키 참조) 유니코드 각 문자는 유니코드 컨소시엄에서 정의한 평면(plane)이라는 곳에 유니코드 코드 포인트로 매핑되어 있는데, 이 코드 포인트를 인코딩 해서 바이트 시퀀스로 변환하는 방법이 UTF에 정의되어 있는 것이다. UTF는 문자를 인코딩할 때 지원되는 바이트 범위를 가지고 있는데, 이 바이트 범위에 따라서 UTF8, UTF16, UTF32로 나누고 있다.
아래 표를 보면 UTF8은 문자를 인코딩할 때 문자당 1~4 바이트 범위를 지원하고 있는데, 다른 인코딩 종류와는 다르게 1바이트도 지원하기 때문에 아스키 코드와 완벽하게 호환되는 장점을 가지고 있다. 또한 1바이트가 필요한 문자는 1바이트만, 2바이트가 필요한 문자는 2바이트만, 3바이트가 필요한 문자는 3바이트만 저장 공간을 요구하기 때문에 메모리나 디스크 공간을 효율적으로 사용한다는 장점도 가지고 있다. 대신 1~4 바이트를 전부 지원하기 때문에 문자열 처리가 복잡하다는 단점을 가지고 있기도 하다. 문자열에서 특정 문자에 임의로 접근하려면 전체 문자를 처음부터 순회하는 수밖에 없으니까 말이다.
*UTF 단어에 suffix로 붙어있는 8, 16, 32는 비트(bit)를 의미하고, 8byte로 나누면 지원되는 최소 바이트 수를 알 수 있다.
UTF32는 문자당 4바이트 단일 범위를 지원하고 있다. 아스키 코드도 4바이트로 인코딩 하고 이모지도 4바이트로 인코딩 하기 때문에 UTF8에 비해서는 문자열 처리가 좀 단순하다. 하지만 이모지를 제외한 대부분의 문자가 1~3바이트 내에서 인코딩이 가능한 것을 생각하면 굳이 4바이트를 사용할 필요가 없기도 하다.
UTF16은 UTF8과 UTF32 사이에서 트레이드 오프로 자리매김하고 있어서 따로 설명은 안하도록 하겠다.

MySQL 8.0은 이 3가지의 유니코드 인코딩 종류를 모두 지원하고 있다. 이 중에서도 UTF8은 MySQL 서버 8.0의 기본 캐릭터 셋이기도 하다. UTF8은 MySQL 서버 내에서 다시 UTF8MB3, UTF8MB4로 정의되어 있는데 이제부터는 이 UTF8과 콜레이션에 대해서 집중적으로 이야기를 해보겠다.
Chracter Set(UTF8)
아까 위에서 UTF가 유니코드 문자 집합을 인코딩 하는 방법을 정의한 것이라고 설명했는데, 여기에서 유니코드 각 문자는 기본 다국어 평면(Basic Multilingual Plane, BMP)이라고 불리우는 평면(Plane 0)에 유니코드 코드 포인트가 매핑되어 있다. 이 평면은 총 16개의 평면이 존재하는데, 0번 평면을 기본 다국어 평면이라고 하고, 1~15번 평면을 보조 평면(Suplmentary Multilingual Plain, SMP)이라고 한다. 일상생활에서 쓰이는 대부분의 문자는 Plane 0인 기본 다국어 평면을 사용한다고 보면 된다.
UTF8은 앞서 말했듯이 1~4바이트 범위의 인코딩을 지원하는 유니코드 변환 포맷이지만, MySQL 8.0 이전에는 4바이트 문자에 대한 요구사항이 없었기 때문인지, 1~3바이트까지만 지원하는 UTF8MB3이라는 별도의 캐릭터 셋이 MySQL 서버의 기본 캐릭터 셋으로 사용되었다. 하지만 MySQL 8.0 부터는 1~4바이트까지 지원하는 UTF8MB4가 MySQL 서버의 기본 캐릭터 셋으로 변경되었다. 때문에 UTF8MB3의 지원 문자 범위는 BMP에 그쳤지만 UTF8MB4는 SMP(보조 평면)까지 얹어서 지원하게 되었다.
유니코드 코드 포인트는 총 16개의 평면에 분산되어 있지만 보조 평면(기본 다국어 평면 제외)에는 아직도 비어있는 공간이 많아서 앞으로 추가되는 문자들은 모두 보조 평면에 정의될 것이다. 이런 이유에서라도 UTF8MB3은 UTF8MB4로 대체되어야 하는게 맞다고 생각하는 바이다.

MySQL 8.0 문서에도 잘 나와있지만 UTF8MB3은 향후 제거될 예정이고 레거시를 위해서 아직 남겨둔 상태이다. UTF8MB3으로 돌아갈 일은 없으니까 UTF8MB4만 잘 기억해두면 될 것 같다.
지금까지 설명한 내용을 핵심만 정리해보겠다.
- MySQL 서버의 캐릭터 셋은 Simple & Complex character set으로 나뉘어져 있다.
- MySQL 8.0은 유니코드 변환 포맷으로 UTF8을 기본으로 사용하고 있다.
- MySQL 8.0 이전에는 UTF8MB3을, 8.0 부터는 UTF8MB4를 사용한다.
Collation
캐릭터 셋에 대한 설명은 이정도로 하고 이제부터는 콜레이션에 대한 설명을 해보겠다. 캐릭터 셋도 중요하지만 콜레이션은 캐릭터 셋보다 더 중요한 개념이니까 집중해서 읽으면 좋을 것 같다.
MySQL 문서를 보면 콜레이션에 대한 정의가 아래와 같이 설명되어 있다.
“A collcation is a set of rules for comparing characters in a character set.”
해석하면 “콜레이션은 캐릭터 셋의 문자들을 비교하기 위한 규칙 세트이다.” 라는 뜻이다. DB 서버 관점에서 보자면 인덱스의 키 값 순서라던가, 문자 비교라던가, ORDER BY 정렬 순서를 따질 때라던가 이 때마다 콜레이션이 사용된다고 보면 된다.
내가 글 처음에 MySQL 서버에는 많은 문자 집합이 존재한다고 했었는데, 콜레이션은 이보다 더 많다. 어떤 콜레이션은 바이트 시퀀스가 정렬 기준이 되기도 하고, 어떤 콜레이션은 코드 포인트가 정렬 기준이 되기도 하기 때문에 캐릭터 셋과 콜레이션은 1:n 관계에 있다.
콜레이션을 필요할 때마다 변경하게 되면 어떻게 될까?
예를 들어 Alphabet이라는 테이블의 레코드가 A, B, C 순으로 정렬되어 있었는데, 콜레이션 변경 사항이 발생해서 B, A, C 순으로 정렬해야 한다면 기존에 저장되어 있던 레코드의 정렬 순서와 앞으로 저장될 레코드의 정렬 순서를 위해서 테이블을 한 번 리빌드(재구성) 해야될 것이다.
콜레이션을 변경하게 되면 데이터 정렬 순서가 바뀌기 때문에 테이블과 인덱스의 리빌드가 필요하다. 서비스 운영 중에 무중단으로 작업해야 한다면 아주 큰 부담이 될 것이다. 그래서 콜레이션은 데이터 타입을 결정하는 것만큼이나 신중하게 결정할 필요가 있다.

이번에는 MySQL 서버 8.0의 기본 캐릭터 셋인 UTF8MB4의 콜레이션에 대해서 좀 더 세부적으로 접근해보겠다.
MySQL 8.0.33 기준으로 utf8mb4 캐릭터 셋의 콜레이션 수는 총 89개이다. 그리고 국가별 언어에 종속적이지 않고 일반적으로 많이 사용되는 콜레이션은 7개 정도이다.
아래 표를 한 번 봐보겠다. 아래 표에서 가장 중요한 건, 문자열 가중치 기준이다.
아까 위에서 콜레이션의 정의는 “캐릭터 셋의 문자들을 비교하기 위한 규칙 세트이다.” 라고 설명했었는데, 이 때 문자를 비교하기 위한 기준이 되는 녀석이 바로 문자열 가중치 기준이다.

그럼 사용자가 문자열 가중치를 확인할 수 있을까?
MySQL 서버에서는 WEIGHT_STRING() 이라는 함수로 문자열의 가중치 값을 확인할 수 있다. syntax는 아래와 같다.
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])예를 들어 문자 A와 문자 B가 정렬될 때는 단순히 알파벳순으로 정렬되는 것이 아니고, WEIGHT_STRING() 함수를 실행했을 때 출력되는 문자열 가중치 값으로 정렬이 된다. (WEIGHT_STRING() 함수는 사용자가 문자열 가중치 값을 확인할 수 있는 기능을 제공하는 함수일 뿐이다)
아래 코드를 보면, 문자 A의 가중치 값은 41, B는 42, a는 61, b는 62인 것을 확인할 수 있다. 이 기준으로 정렬을 한다면 41부터 62까지 순서대로 정렬되는 것이다.
mysql> CREATE TABLE collation_table (name CHAR(1)) COLLATE=utf8mb4_0900_bin;
Query OK, 0 rows affected (0.07 sec)
mysql> SHOW CREATE TABLE collation_table;
+-----------------+----------------------------------------------+
| Table | Create Table |
+-----------------+----------------------------------------------+
| collation_table | CREATE TABLE `collation_table` (
`name` char(1) COLLATE utf8mb4_0900_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-----------------+----------------------------------------------+
1 row in set (0.00 sec)
mysql> INSERT INTO collation_table VALUES('A'),('b'),('a'),('B');
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> SELECT name, WEIGHT_STRING(name) FROM collation_table ORDER BY name;
+------+------------------------------------------+
| name | WEIGHT_STRING(name) |
+------+------------------------------------------+
| A | 0x41 |
| B | 0x42 |
| a | 0x61 |
| b | 0x62 |
+------+------------------------------------------+
4 rows in set (0.00 sec)
그런데 이 기준이 항상 동일할까? 아니 꼭 그렇지는 않다.
아래 그림에서 왼쪽은 latin1_general_cs 콜레이션의 문자열 가중치 맵을 그대로 복사해서 이름만 바꿔놓은 latin1_silver_cs(Not modified) 콜레이션이고, 오른쪽은 latin1_general_cs 콜레이션에서 문자 A와 문자 a의 문자열 가중치 값을 각 각 99와 77로 변경한 latin1_silver_cs(Modified) 콜레이션이다.
이렇게 커스텀 가중치 맵을 만들어놓고 대문자 A와 소문자 a를 정렬해보도록 하겠다.
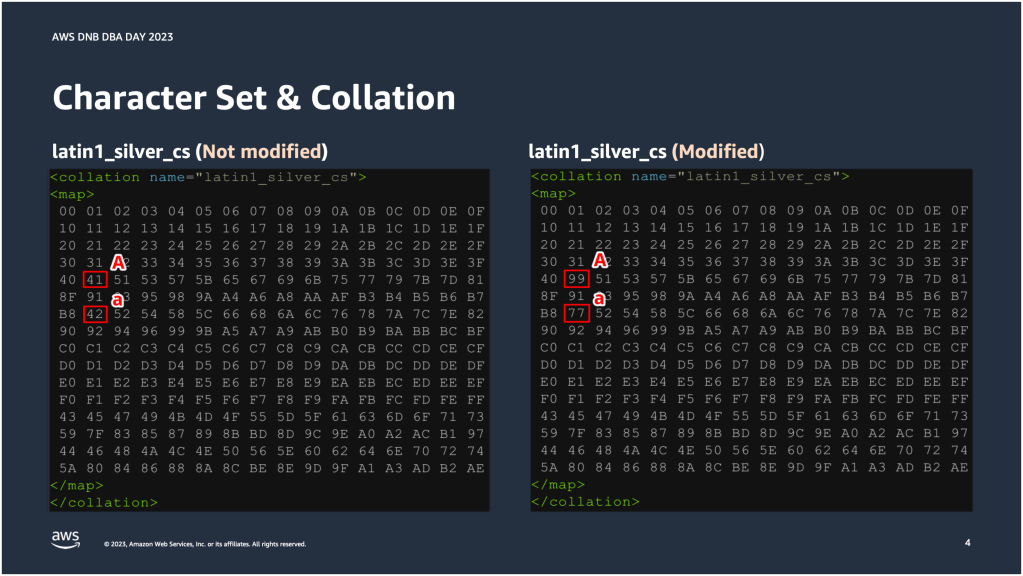
아래 장표에서 왼쪽이 수정하지 않은 콜레이션의 결과이고, 오른쪽이 수정한 콜레이션의 결과이다. 정렬 결과를 보면 알겠지만 콜레이션에 따라서 동일한 문자를 다르게 정렬한다는 것을 알 수 있다. 문자열 가중치 맵을 수정하지 않았던 콜레이션은 대문자 A를 우선 정렬했고, 문자열 가중치 맵을 수정했던 콜레이션은 소문자 a를 우선 정렬했다. 이렇게 문자 정렬 기준은 콜레이션에 따라서 다를 수 있기 때문에 항상 특정 문자가 먼저 정렬된다고 볼 수는 없다.
그래서 우리는 문자들이 콜레이션에 따라 다르게 정렬되고 비교될 수 있다는 사실을 꼭 기억하고 있어야 한다.

그럼 아래 장표로 다시 돌아와서, utf8mb4 캐릭터 셋의 콜레이션에 대해서 계속 이야기해보겠다. 국가별 언어에 종속적이지 않은 7개의 콜레이션은 각기 다른 문자열 가중치 기준을 가지고 있다.
먼저, code point는 유니코드에서 각 문자를 고유하게 식별할 수 있는 값이다. 예를 들어 문자 A의 코드 포인트가 U+0041이고, 문자 B의 코드 포인트가 U+0042라면, utf8mb4_bin 콜레이션을 사용할 때는 이 코드 포인트 값으로 문자를 비교하거나 정렬하게 되는 것이다.
utf8mb4_general_ci 콜레이션의 문자열 가중치 기준을 보면 MySQL Custom 이라고 적혀있는데 정확하게는 utf8mb4_unicode_ci와 비교했을 때 좀 더 레거시한 콜레이션이라고 보면 된다.
예를 들어, 독일어에서 사용되는 에스체트(scharfes S)라고 불리우는 ‘ß’ 문자는 ‘ss’ 소리를 나타내기도 하는데, 이 때문에 독일에서는 ‘ß’와 ‘ss’ 문자를 다르다고 구분짓지 않는다. ‘뜻하다’ 라는 뜻을 지닌 ‘heißen’ 이라는 단어는 ‘heissen’ 으로도 쓸 수 있다.
아래는 MySQL 서버에서 utf8mb4_general_ci, utf8mb4_unicode_ci 콜레이션으로 ‘ß’와 ‘ss’ 문자가 서로 동일한 문자열 가중치 값을 가지는지 비교 수행한 결과이다. utf8mb4_unicode_ci 콜레이션에 사용되는 UCA 4.0.0은 독일어를 인식하기 때문에 ‘ß’와 ‘ss’ 문자가 동일하다고 판단하고 있다.
mysql> SELECT ('ß' = 'ss' COLLATE utf8mb4_general_ci), ('ß' = 'ss' COLLATE utf8mb4_unicode_ci);
+------------------------------------------+------------------------------------------+
| ('ß' = 'ss' COLLATE utf8mb4_general_ci) | ('ß' = 'ss' COLLATE utf8mb4_unicode_ci) |
+------------------------------------------+------------------------------------------+
| 0 | 1 |
+------------------------------------------+------------------------------------------+
1 row in set (0.00 sec)
그 다음 문자열 가중치 기준으로 UCA라는 기준이 있는데, 이 기준의 경우에는 UCA <version>으로 각 콜레이션의 가중치 기준을 다르게 가져가고 있다. UCA는 Unicode Collation Algorithm의 약자이고, 유니코드의 각 문자를 어떻게 비교하고 정렬할지 정의되어 있는 유니코드의 표준 콜레이션 알고리즘이라고 보면 된다. UCA 버전이 올라갔다는 건, 새로운 유니코드 문자가 추가되거나 문자의 정렬 비교 규칙이 변경되었다는 것이다.
UCA는 현재 기준으로 16.0.0 버전까지 나와있는 상태이고, 4.0.0은 2004년 1월에, 5.2.0은 2009년 10월에, 9.0.0은 2016년 5월에 발행되었다. MySQL 8.0.0의 릴리즈가 2016년 9월인 것을 보면, 출시 당시에는 최신 버전인 UCA 9.0.0을 적용했다는 것을 알 수 있다.
그리고 마지막 문자열 가중치 기준으로 encoding bytes라는 기준이 있는데, 이건 저장된 바이너리 데이터를 기준으로 문자를 정렬 및 비교한다는 의미이다. 대부분의 인코딩 체계에서는 코드 포인트의 순서대로 바이트를 할당하기 때문에 코드 포인트를 기준으로 하는 utf8mb4_bin과 문자의 정렬 순서가 동일하다.
물론 완벽하게 일치하지는 않는다. utf16 같은 경우에는 모든 유니코드 문자를 4바이트로 인코딩하기 때문에 4바이트로 인코딩된 1바이트 문자는 코드 포인트와 정렬 순서가 다를 수도 있다.
그리고 참고로, utf8mb4_bin은 PAD SPACE 옵션을 가지고 있어서 후행에 공백이 있다면 공백 처리를 하고, utf8mb4_0900_bin은 NO PAD여서 후행에 공백이 있어도 공백 처리를 하지 않는다.
마지막으로 콜레이션의 네이밍 컨벤션을 살짝만 언급하겠다. 유니코드 콜레이션의 네이밍은 복잡한 규칙을 가지고 있지는 않고, 아래처럼 첫 번째는 캐릭터 셋, 두 번째는 언어종속, 세 번째는 UCA 버전, 마지막은 민감도를 나타낸다. 아마 이중에서 민감도에 대해서 궁금해 할텐데 민감도는 콜레이션이 문자 분류를 얼마나 엄격하게 구분할 것인지를 나타내는 기준이라고 생각하면 된다. 예를 들어 utf8mb4_0900_ai_ci는 민감도가 ai_ci 인데, 이건 액센트랑 대소문자를 구분하지 않겠다(accent insensitive, case insensitive)라는 의미이다. 민감도가 as_cs라면 액센트와 대소문자를 엄격하게 구분하기 때문에(accent sensitive, case sensitive) 그만큼 문자 분류 규칙이 민감한 콜레이션이 되겠다. 유니코드에서는 기본적으로 세 단계의 콜레이션 민감도가 존재하는데 좀 더 자세한 내용은 뒤에서 다루도록 하겠다.
문자집합_언어종속_UCA버전_민감도Examples of Collation Comparison
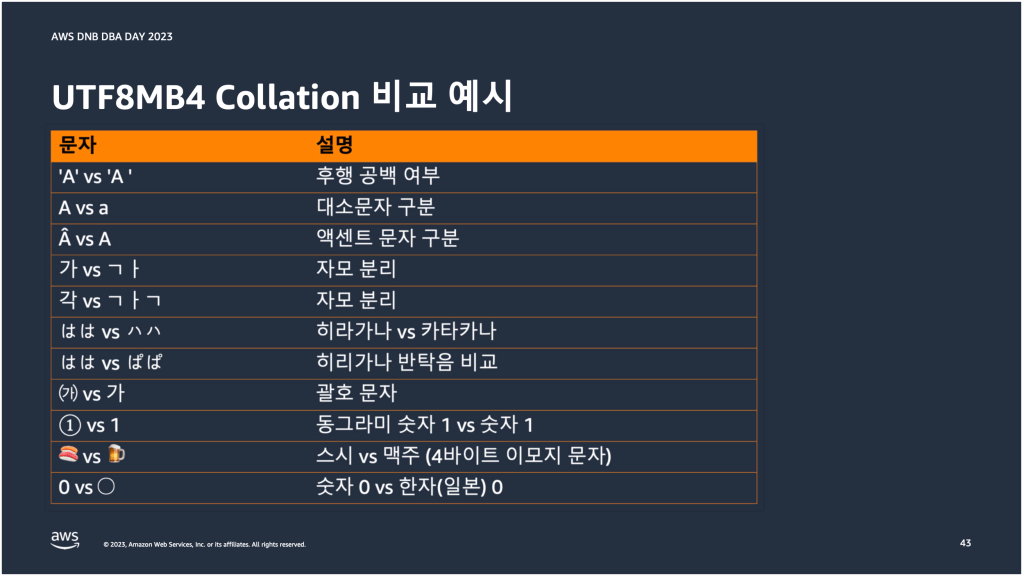
이번에는 utf8mb4 콜레이션마다 실제 문자를 어떻게 비교하는지 확인해보려고 한다. 후행 공백 여부, 대소문자 구분, 액센트 문자 구분, 자모 분리 등에 따라 문자를 어떻게 비교하는지 대표적으로 이슈가 되는 것들 위주로 가져와봤다. 아마 ‘가’와 ‘ㄱㅏ’의 비교는 너무나도 잘 알려져 있어서 비교 결과는 이미 알고 있을 것이다. 하지만 왜 그런 결과가 나왔을까? 몇 가지 문자 비교 예시를 보면서 그 이유도 함께 살펴보도록 하겠다.
아래 표는 위의 비교 예시를 true(=), false(≠)로 나타낸 결과이다. 항목이 많아서 몇 가지 결과만 짚어서 얘기할텐데 나머지는 한 번씩 살펴보면 좋을 것 같다.
먼저 아래 표 왼쪽 상단의 녹색 동그라미를 봐볼겠다. utf8mb4_bin 콜레이션은 문자 ‘A’와 ‘A ‘의 문자열 가중치 값이 동일하다고 판단하는 반면에, utf8mb4_0900_bin 콜레이션은 다르다고 판단하고 있다. 아까 위에서 두 콜레이션의 문자 정렬 순서가 동일하다고 했었는데, 이렇게 예외가 발생한 이유는 utf8mb4_bin 콜레이션이 PAD SPACE 속성을 가지고 있어서 공백이 들어간 문자는 공백처리를 하기 때문이다. utf8mb4_bin 콜레이션 입장에서는 공백 문자가 없는 것처럼 인식하는 셈이다. 그래서 공백이 들어간 문자를 제외하고는 비교 결과가 동일하다.
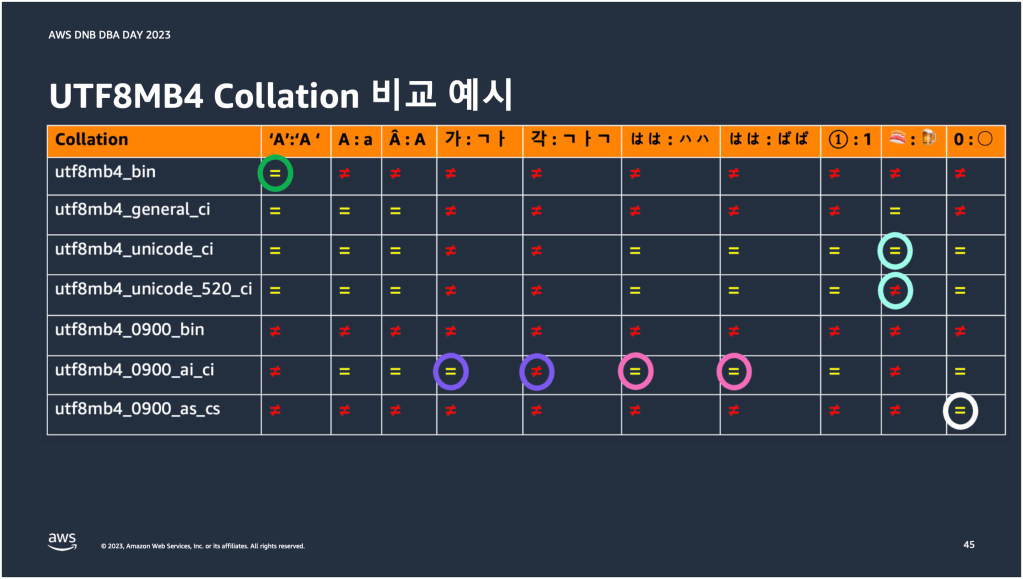
이번에는 표 오른쪽 상단의 형광색 동그라미를 봐보겠다. utf8mb4_unicode_ci 콜레이션은 스시 이모티콘과 맥주 이모티콘이 동일한 문자열 가중치 값을 가지고 있다고 판단하는 반면에, utf8mb4_unicode_520_ci 콜레이션은 반대로 판단하고 있다. 두 콜레이션은 유니코드 콜레이션 알고리즘 버전이 다르다. utf8mb4_unicode_ci 콜레이션은 UCA 4.0.0을 기반으로 하고 있고, utf8mb4_unicode_520_ci 콜레이션은 UCA 5.2.0을 기반으로 하고 있다. 버전만 다른 동일한 콜레이션 알고리즘임에도 두 이모티콘의 문자열 가중치를 서로 다르게 판단하는 이유는 알고리즘 버전 차이에 있다. 여기서는 간단하게 알고리즘 버전이 올라가면서 문자 분류 규칙이 좀 더 세분화 되었다고 생각하면 될 것 같다. UCA 5.2.0 알고리즘에는 스시와 맥주 이모티콘을 분류할 수 있는 규칙이 추가된 것이다.
표 중앙 하단에서 오른쪽 분홍색 동그라미를 봐보겠다. 일본어의 히라가나 はは는 어머니를 의미하고, 카타카나 ハハ는 발음은 동일한데 별다른 의미를 지니고 있지 않다. 일본어의 특성상 두 단어는 다르게 사용되는 것이 맞다. 하지만 utf8mb4_0900_ai_ci 콜레이션에서는 이 두 단어의 문자열 가중치가 동일하다고 판단한다. 또 발음은 다르지만 はは와 ぱぱ도 동일하다고 판단한다.
이런 현상이 발생하는 이유는 콜레이션 민감도에 있다. as_cs 민감도는 액센트와 대소문자를 구분하는 민감도(accent sensitive, case sensitive)인데, 액센트와 대소문자를 구분하지 못하는 ai_ci 민감도와는 다르게 발음이 비슷한 히라가나와 카타카나를 구분할 수 있다. 이 말인 즉슨 as_cs 민감도가 붙은 콜레이션은 일본어 모음 발음에 관계없이 두 단어를 분류할 수 있고, ai_ci 민감도가 붙은 콜레이션은 두 단어를 분류할 수 없다는 말이다.
그래서 utf8mb4_0900_ai_ci 콜레이션은 일본어 모음 발음이 동일한 두 단어의 문자열 가중치가 동일하다고 판단하는 거고, utf8mb4_0900_as_cs 콜레이션은 다르다고 판단하는 것이다.
표 오른쪽 하단의 하얀색 동그라미는 숫자 0과 문자 〇를 비교한 결과이다. 이건 utf8mb4_0900_as_cs 콜레이션이 다른 문자들의 비교는 false로 판단하는데, 숫자 0과 문자 〇만 true로 판단하고 있다는 부분만 체크하고 넘어가면 될 것 같다.
마지막으로 표 중앙 하단에서 왼쪽 보라색 동그라미이다. 보면 문자 ‘가‘와 문자 ‘ㄱㅏ‘, 문자 ‘각‘과 문자 ‘ㄱㅏㄱ‘의 문자열 가중치 비교 결과를 각각 true, false라고 판단하고 있다. 아마 한국인들에게 ‘ㄱㅏ’와 ‘ㄱㅏㄱ’을 읽어보라고 하면 거의 대부분 가와 각이라고 발음할 것이다. 하지만 또 검색창에 ‘가’와 ‘각’을 검색했을 때, ‘ㄱㅏ’와 ‘ㄱㅏㄱ’이 검색되는 것은 이상하다고 생각할 것이다. 데이터베이스 관점에서는 어떨까? 데이터베이스 관점에서 봤을 때는 전자는 크게 중요하지 않다. 후자와 같은 문제가 더 중요해. ‘가’를 검색하면 ‘가’만 나와야 하는데 ‘ㄱㅏ’와 같은 엉뚱한 데이터(DB 관점에서)가 검색되면 안되니까 말이다. 그런데 또 ‘각’을 검색하면 ‘ㄱㅏㄱ’이 검색되지 않는 것도 이상하다. 왜 그럴까.

몇 가지 콜레이션 비교 예시를 통해서 각 콜레이션마다 문자열 가중치 값을 다르게 판단한다는 사실을 알게 되었다. 하지만 콜레이션이 어떤 원리로 문자의 가중치 값을 판단하는지는 살펴보지 않았다.
그래서 이번에는 ‘가’와 ‘ㄱㅏ’, ‘각’과 ‘ㄱㅏㄱ’의 문자 비교 예시를 통해서 콜레이션이 어떻게 동작하는지 살펴보려고 한다. 정확하게는 MySQL 서버 8.0의 기본 콜레이션인 utf8mb4_0900_ai_ci 콜레이션의 동작 방식을 살펴보는 것이다.
Collation 동작 방식
콜레이션을 통해서 문자를 비교할 때는 문자열에 대한 가중치 값을 계산한 후에 비교를 수행한다. 이 때 가중치 값은 DUCET(Default Unicode Collation Element Table)이라는 테이블에 정의된 가중치 값을 사용하는데, 여기서 DUCET은 유니코드 문자를 정렬하기 위해서 기본 규칙을 정의해놓은 표(테이블)를 의미한다. 아래 URL 경로에 들어가보면 UCA 버전별로 allkeys.txt 파일에 유니코드 코드 포인트와 가중치 값이 정의되어 있는걸 확인할 수 있다. (DUCET이 allkeys.txt 파일에 정의되어 있다는 말이야)
https://www.unicode.org/Public/UCA
내가 문자열 가중치를 설명할 때 간단하게 문자열 가중치 값이라고만 설명했지만 사실은 좀 더 세부적으로 정의가 되어 있다. 아래 장표의 세 번째 줄의 내용과 같이 문자열의 가중치 값은 Primary, Secondary, Tertiary 세 단계로 구성되어 있다. 한글같은 경우에는 음절이 조합된 완성문자여서 ‘가’와 ‘각’이라면 각 음절을 자음(ㄱ), 모음(ㅏ)으로 분해해서 각 문자의 가중치 값을 조합한 후에 비교 작업을 수행한다. 아래 노란색 글씨는 HANGUL LETTER KIYEOK에 대한 유니코드 코드 포인트와 가중치 값을 적어놓은건데, 이건 한글 ㄱ(기역)에 해당된다. 그리고 네 번째 줄에 보면 각 가중치 단계를 콜레이션 민감도(ai_ci.as_ci.as_as)로 치환해두었는데, MySQL 서버 8.0의 기본 콜레이션인 utf8mb4_0900_ai_ci는 민감도가 ai_ci이기 때문에 가중치 값으로 문자를 비교할 때 3단계 중 Primary 단계만 사용한다. utf8mb4_0900_as_cs 콜레이션이라면 Secondary, Tertiary 단계까지 사용하고 말이다.

콜레이션의 동작 방식을 살짝 맛봤으니 이제 ‘가’,’ㄱㅏ’,’각’,’ㄱㅏㄱ’에 대한 내용을 좀 더 살펴보려고 한다.
‘가’는 자음과 모음이 조합된 하나의 완성문자이다. 완성 문자이기 때문에 초성(ㄱ)과 중성(ㅏ)으로 나눌 수 있어. 그리고 ‘각’은 받침 글자도 존재하기 때문에 종성(ㄱ)까지 나눌 수 있다. 반면에 ‘ㄱㅏ’는 자음과 모음이 조합된 완성문자가 아니라 한글 문자 ‘ㄱ’과 ‘ㅏ’가 나란히 놓여있는 하나의 문자열이다. ‘ㄱㅏㄱ’도 마찬가지이고. 그래서 ‘가’, ‘각’과 ‘ㄱㅏ’, ‘ㄱㅏㄱ’은 언어적 특성부터가 다르다.
배경 설명은 여기까지 하고, 내용을 다시 봐보겠다. 아래 장표는 한글 초성 ‘ㄱ’, 중성 ‘ㅏ’, 종성 ‘ㄱ’과 한글 문자 ‘ㄱ’,’ㅏ’의 유니코드 코드 포인트와 문자열 가중치 값을 DUCET에서 가져와본 것이다. 가장 왼쪽의 4자리 문자(ex: 1100)가 유니코드 코드 포인트를 의미하고, 대괄호안의 12자리 문자(ex: .3BF5.0020.0002)가 문자열 가중치 값을 의미한다. 이걸 보면 왜 utf8mb4_0900_ai_ci 콜레이션이 ‘가’와 ‘ㄱㅏ’는 문자열 가중치 값이 동일하다고 판단하면서, ‘각’과 ‘ㄱㅏㄱ’은 다르다고 판단했는지 알 수 있다.
아까 ai_ci 민감도는 콜레이션 민감도 3단계 중에 Primary 단계만 사용한다고 했었다. 아래에 색이 칠해진 부분이 Primary 단계의 가중치 값이다. 먼저 문자 ‘가’를 살펴볼게. ‘가’는 초성 ‘ㄱ’과 중성 ‘ㅏ’에 해당하는 가중치 값을 보면 된다. 초성 ‘ㄱ’는 3BF5이고, 중성 ‘ㅏ’는 3C73이다. 이 2개 가중치 값을 조합하면, 3BF53C73이 되고 MySQL 서버에서 WEIGHT_STRING(‘가’) 함수 값도 0x3BF53C73으로 동일하다는걸 확인할 수 있다. 이번에는 ‘ㄱㅏ’를 살펴보겠다. ‘ㄱ’과 ‘ㅏ’는 둘 다 한글 문자이다. 그렇기 때문에 한글 문자 ‘ㄱ’과 ‘ㅏ’에 해당하는 가중치 값을 보면 된다. 한글 문자 ‘ㄱ’은 3BF5이고, 한글 문자 ‘ㅏ’는 3C73이다. 이 2개 가중치 값을 조합하면, 3BF53C73이 되고 MySQL 서버에서 WEIGHT_STRING(‘가’) 함수 값도 0x3BF53C73으로 동일하다는걸 확인할 수 있다. 결국 ‘가’와 ‘ㄱㅏ’는 문자열 가중치 값이 각각 0x3BF53C73, 0x3BF53C73으로 동일하기 때문에 uf8mb4_0900_ai_ci 콜레이션에서 동일하다고 판단하는 것이다.
다음으로 ‘각’과 ‘ㄱㅏㄱ’을 살펴보겠다. ‘각’의 초성 ‘ㄱ’은 3BF5이고 중성 ‘ㅏ’는 3C73, 종성 ‘ㄱ’은 3CD1이다. 조합하면 3BF53C733CD1이 된다. 한글 문자 ‘ㄱ’은 3BF5이고, 한글 문자 ‘ㅏ’는 3C73이고, 다시 한글 문자 ‘ㄱ’은 3BF5야. 조합하면 3BF53C733BF5가 된다. ‘ㄱㅏㄱ’에서 한글 문자 ‘ㄱ’의 가중치 값이 한 번 더 사용되면서 ‘각’과는 다른 가중치 값이 나왔다. 그래서 ‘각’과 ‘ㄱㅏㄱ’은 문자열 가중치 값이 각각 0x3BF53C733CD1, 0x3BF53C733BF5이기 때문에 다르다고 판단하는 것이다.

추가로 utf8mb4_0900_as_cs 콜레이션의 문자열 비교도 살펴볼게. as_cs 민감도는 콜레이션 민감도 3단계를 전부 사용한다. utf8mb4_0900_ai_ci 콜레이션에서 ‘가’의 가중치 값은 0x3BF53C73이었지만, utf8mb4_0900_as_cs에서는 0x3BF53C73000000200020000000020002가 된다. 그리고 ‘ㄱㅏ’는 ai_ci에서 0x3BF53C73이었지만, as_cs에서는 0x3BF53C73000000200020000000020004가 된다. Secondary, Tertiary 단계의 가중치 값을 사용하면서 문자 비교 기준이 이전보다 세분화되었다. utf8mb4_0900_as_cs 콜레이션이 ‘가’, ‘각’, ‘ㄱㅏ’, ‘ㄱㅏㄱ’을 전부 다르다고 판단한 이유가 바로 여기에 있는 것이다. 정확히는 Tertiary 단계의 가중치 값(0004) 차이로 인해 각 문자의 가중치 값이 다르다고 판단하는 것이다.

아래 장표는 MySQL 서버를 업그레이드할 때나, 마이그레이션 작업 수행할 때 콜레이션 선택에 있어서 고려해야될 것들을 정리한건데, 요건 참고삼아 봐주면 될 것 같다.

결론
이 글을 읽는 누군가의 ‘ㄱ’ 다음에 ‘ㄴ’ 이기 때문에, ‘a’ 다음에 ‘b’ 이기 때문에 ㄱㄴㄷ, abc순으로 문자가 정렬된다 라는 생각이 콜레이션의 문자열 가중치 기준에 의해 문자가 정렬된다 라는 좀 더 명확한 사실로 바뀌었으면 좋겠다.

댓글 남기기