
MySQL 서버에서 쿼리의 WHERE절에 IN 조건을 작성할 때는 일반적인 방식이 아닌 Row constructor 방식을 사용할 수 있다.
쿼리로 표현하면 다음과 같다.
(이 글에서는 Multi IN 조건이라고 부르겠다.)
SELECT * FROM test WHERE (seq1, seq2) IN ((value1, value2), (value3, value4))그리고 이를 다시 동일한 결과셋을 반환하는 쿼리로 작성하면 다음과 같다.
(이 글에서는 General IN 조건이라고 부르겠다.)
SELECT * FROM test WHERE (seq1 = value1 AND seq2 = value2) OR (seq1 = value3 AND seq2 = value4)
그런데 특정 조건(쿼리의 조건을 의미하지 않음)에서는 Multi IN clause 실행 계획에서 불명확한 경고 문구가 발생하는 오류가 있다.
이 경고 문구가 발생하는 조건은 다음과 같다.
// 테이블 생성
mysql>
CREATE TABLE `test` (
`id` int NOT NULL AUTO_INCREMENT,
`group_id` varchar(50) NOT NULL,
`member_id` varchar(50) NOT NULL,
`remark` varchar(50) NOT NULL,
`created_at` datetime(6) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_groupid_memberid` (`group_id`,`member_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
// 데이터
mysql> select * from test limit 20;
+----+--------------------+------------+--------+----------------------------+
| id | group_id | member_id | remark | created_at |
+----+--------------------+------------+--------+----------------------------+
| 1 | 100 | 2b0377529e | test58 | 2023-12-20 11:47:51.000000 |
| 2 | 1000 | 2fa7b0e89e | test7 | 2023-12-20 11:47:59.000000 |
| 3 | 10000 | aaa123bbb | test61 | 2023-12-20 11:48:02.000000 |
| 4 | 10000 | aaa123bbb | test87 | 2023-12-20 11:48:04.000000 |
| 5 | 10000 | aaa123bbb | test52 | 2023-12-20 11:48:11.000000 |
| 6 | 10000 | 373f55f49e | test1 | 2023-12-20 11:48:12.000000 |
| 7 | 10000 | 379f25429e | test48 | 2023-12-20 11:48:12.000000 |
| 8 | 10000 | 37ce484a9e | test38 | 2023-12-20 11:48:13.000000 |
| 9 | 10000 | 39b6a9409e | test46 | 2023-12-20 11:48:16.000000 |
| 10 | 100000 | 3df3c5749e | test18 | 2023-12-20 11:48:23.000000 |
| 11 | 100 | 408e60289e | test51 | 2023-12-20 11:48:27.000000 |
| 12 | 1000 | 43c9072a9e | test0 | 2023-12-20 11:48:33.000000 |
| 13 | 10000 | 37ce484a9e | test51 | 2023-12-20 11:48:36.000000 |
| 14 | 10000 | 464aac4c9e | test53 | 2023-12-20 11:48:37.000000 |
| 15 | 10000 | 37ce484a9e | test15 | 2023-12-20 11:48:38.000000 |
| 31 | 10924.853394669344 | 0441d9cc9f | test4 | 2023-12-20 21:33:45.000000 |
| 32 | 88668.79408123791 | 155f84e89f | test30 | 2023-12-20 21:34:14.000000 |
| 33 | 86383.43465177662 | 1663c1c49f | test40 | 2023-12-20 21:34:15.000000 |
| 34 | 43266.139312895146 | 1af129029f | test94 | 2023-12-20 21:34:23.000000 |
| 35 | 44605.76273929865 | 1af143e29f | test38 | 2023-12-20 21:34:23.000000 |
+----+--------------------+------------+--------+----------------------------+
// Multi IN clause 쿼리
mysql> explain select * from test where (group_id, member_id) in (('10000', 'aaa123bbb'), ('10000', '37ce484a9e'));
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test | NULL | range | ix_groupid_memberid | ix_groupid_memberid | 404 | NULL | 6 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-------------+
Warning (Code 1739): Cannot use ref access on index 'ix_groupid_memberid' due to type or collation conversion on field 'group_id'
Warning (Code 1739): Cannot use ref access on index 'ix_groupid_memberid' due to type or collation conversion on field 'group_id'
위의 쿼리는 “group_id 필드에서 타입 또는 콜레이션 변환 때문에 ix_groupid_memberid 인덱스에서 ref 액세스 방식을 사용할 수 없다.” 라는 오류(경고)를 반환한다.
Warning (Code 1739): Cannot use ref access on index 'ix_groupid_memberid' due to type or collation conversion on field 'group_id'앞서 원인이 불명확한 오류라고 말한 이유는, 아래의 쿼리 실행계획을 보면 알 수 있다.
동일한 결과셋을 보장하면서도 액세스 방식 또한 인덱스 레인지 스캔을 사용하는 쿼리인데, Multi IN clause 쿼리와는 다르게 실행 계획에 경고가 반환되지 않는다.
mysql> explain select * from test where (group_id = '10000' and member_id = 'aaa123bbb') OR (group_id = '10000' and member_id = '37ce484a9e');
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | test | NULL | range | ix_groupid_memberid | ix_groupid_memberid | 404 | NULL | 6 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------------+---------------------+---------+------+------+----------+-----------------------+
눈에 보이지 않는 어떤 작업이 옵티마이저 내부에서 동작하는 것일까?
그래서 이번 글에서는 Multi IN 조건의 실행 계획에서 Warning (Code: 1739)이 발생하는 원인을 분석해보고자 한다.
다소 분석 내용이 길 수도 있는데, 인내심을 가지고 읽다보면 MySQL 서버와 친해지는 계기를 마련하게 될 것이다.
- Check Handler status
- MySQL Server Debugging
- mysqld trace file comparision
- MySQL Server Source Debugging
- Thread memory usage
- Conclusion
Check Handler status
먼저 Multi IN clause와 General IN clause 쿼리에서 스토리지 엔진으로 핸들러 API를 요청하는 오퍼레이션에 차이가 있는지 확인해본다.
// Multi IN clause QUERY
mysql> select * from test where (group_id, member_id) in (('10000', 'aaa123bbb'), ('10000', '37ce484a9e'));
mysql> show status like '%handler%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 0 |
| Handler_read_key | 2 |
| Handler_read_last | 0 |
| Handler_read_next | 6 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
// Initiate handler status
mysql> flush status;
// General IN clause QUERY
mysql> select * from test where (group_id = '10000' and member_id = 'aaa123bbb') OR (group_id = '10000' and member_id = '37ce484a9e');
mysql> show status like '%handler%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 0 |
| Handler_read_key | 2 |
| Handler_read_last | 0 |
| Handler_read_next | 6 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
위 결과에서 볼 수 있듯이 Multi IN clause와 General IN clause 방식 모두 2번의 Handler_read_key와 6번의 Handler_read_next API가 호출된 것을 확인할 수 있다.
그러므로, 2가지의 쿼리 방식은 레코드를 찾는 오퍼레이션 비용이 동일하다고 볼 수 있다.
MySQL Server Debugging
이전에 다른 블로그 포스팅에서도 언급했듯이 MySQL 서버는 2가지 방식의 디버깅을 지원한다. 첫 번째는 Server 디버깅이고, 두 번째는 Client 디버깅이다. 이번에는 MySQL Server에서 어떤 일이 발생하는지 확인하는 것이 목적이기 때문에 Server 디버깅 방식으로 트레이스를 로깅한다.
디버깅 수행은 간단하다. 아래와 같이 mysqld 실행파일에 –debug 옵션 플래그를 넣어서 프로세스를 실행하면 된다(debug 옵션 플래그를 적용하기 위해서는 전제 조건으로 MySQL Server를 디버그 모드로 빌드해야 한다. 빌드 방법은 다음 또는 이전 블로그 내용을 참고하면 된다.).
# MySQL Server 디버그 모드 수행
# 디버깅 트레이스가 /tmp/mysqld.trace 파일에 기록됨
$ mysqld -u root --debug &
디버그 모드로 빌드한 순간부터 /tmp/mysqld.trace 파일에 MySQL 서버의 활동이 기록되기 시작하는데, 수십 GB의 용량으로 늘어나는 것을 방지하기 위해 쿼리를 실행하기 직전까지의 트레이스 내용은 삭제하는 것을 추천한다.
# Multi IN clause 쿼리 수행
mysql> explain select * from test where (group_id, member_id) in (('10000', 'aaa123bbb'), ('10000', '37ce484a9e'));
# 비교 분석을 위해 로깅된 트레이스 파일 복사
$ sudo cp /tmp/mysqld.trace /tmp/mysqld_multi_in_clause.trace
# mysqld.trace 파일 삭제 후, general IN Clause 쿼리 수행
mysql> explain select * from test where (group_id = '10000' and member_id = 'aaa123bbb') OR (group_id = '10000' and member_id = '37ce484a9e');
# 로깅된 트레이스 파일 복사
$ sudo cp /tmp/mysqld.trace /tmp/mysqld_general_in_clause.trace
트레이스 파일의 비교 분석을 위해 Multi IN clause 방식으로 쿼리를 수행할 때 로깅된 트레이스와, General IN clause 방식으로 쿼리를 수행할 때 로깅된 트레이스를 별도의 파일로 복사한다.
mysqld trace file comparision
트레이스 파일에는 쿼리를 수행하기 위해 3-way-handshake를 맺는 부분부터 authorization, lexical analysis등 쿼리를 종료하기까지의 전과정이 클래스, 함수 호출 등의 형태로 로깅된다.
이 중 우리가 살펴봐야할 부분은 트레이스의 공통된 부분을 제외한 개별 트레이스 내용이다. 트레이스의 내용을 확인하는 절차는 3단계에 걸쳐 이루어진다.
Phase 1) explain에서 발생한 경고 문구가 로깅되어 있는 지점 확인
Phase 2) 경고 문구가 발생한 지점의 소스파일 확인
Phase 3) 호출된 함수 순서대로 분석
위와 같이 3단계로 나누어 트레이스 파일 내용을 확인해보면 Multi IN clause 쿼리의 트레이스에서 오류 관련 지점을 찾을 수 있다. General IN clause 트레이스는 오류 관련 지점 이외에 다른 차이는 없는지 확인하는 용도로만 사용하면 된다.
아래는 Multi IN clause 트레이스에서 오류 관련 지점의 트레이스 내용만 발췌한 것이다. 내용을 한 번 보자.
먼저 오류는 875020 라인의 push_warning_printf() 함수를 호출하면서부터 발생한다는 것을 확인할 수 있다. 875023 라인에 오류에 대한 내용이 로깅되어 있다. 875037 라인에 오류 내용이 한 번 더 로깅된 것은 Handler_read_key API를 두 번 호출했기 때문이며, 이에 따라 push_warning_printf() 함수 또한 두 번 호출된 것을 확인할 수 있다.
여기까지만 확인했을 때 얻어낸 정보는 다음과 같다.
- sql_optimizer.cc 파일에서 오류 발생
- push_warning_printf() 함수를 호출하면서 오류 발생
874993 T@8: | | | | | | | | THD::enter_stage: 'statistics' /Users/silverlee/mysql_custom/mysql-server/sql/sql_optimizer.cc:693
874994 T@8: | | | | | | | | >PROFILING::status_change
874995 T@8: | | | | | | | | <PROFILING::status_change
874996 T@8: | | | | | | | | >JOIN::make_join_plan
874997 T@8: | | | | | | | | | >int ha_innobase::info_low
874998 T@8: | | | | | | | | | | >ha_innobase::update_thd
874999 T@8: | | | | | | | | | | | ha_innobase::update_thd: user_thd: 0x11e809e00 -> 0x11e809e00
875000 T@8: | | | | | | | | | | | >innobase_trx_init
875001 T@8: | | | | | | | | | | | <innobase_trx_init
875002 T@8: | | | | | | | | | | <ha_innobase::update_thd
875003 T@8: | | | | | | | | | | >dict_index_t *ha_innobase::innobase_get_index
875004 T@8: | | | | | | | | | | <dict_index_t *ha_innobase::innobase_get_index
875005 T@8: | | | | | | | | | | >dict_index_t *ha_innobase::innobase_get_index
875006 T@8: | | | | | | | | | | <dict_index_t *ha_innobase::innobase_get_index
875007 T@8: | | | | | | | | | <int ha_innobase::info_low
875008 T@8: | | | | | | | | | opt: (null): starting struct
875009 T@8: | | | | | | | | | opt: table_dependencies: starting struct
875010 T@8: | | | | | | | | | opt: (null): starting struct
875011 T@8: | | | | | | | | | opt: table: "`test`"
875012 T@8: | | | | | | | | | opt: row_may_be_null: 0
875013 T@8: | | | | | | | | | opt: map_bit: 0
875014 T@8: | | | | | | | | | opt: depends_on_map_bits: starting struct
875015 T@8: | | | | | | | | | opt: depends_on_map_bits: ending struct
875016 T@8: | | | | | | | | | opt: (null): ending struct
875017 T@8: | | | | | | | | | opt: table_dependencies: ending struct
875018 T@8: | | | | | | | | | opt: (null): ending struct
875019 T@8: | | | | | | | | | info: add_key_field for field group_id
875020 T@8: | | | | | | | | | >push_warning_printf
875021 T@8: | | | | | | | | | | enter: warning: 1739
875022 T@8: | | | | | | | | | | >push_warning
875023 T@8: | | | | | | | | | | | enter: code: 1739, msg: Cannot use ref access on index 'ix_groupid_memberid' due to type or collation conversion on field 'group_id'
875024 T@8: | | | | | | | | | | | >*THD::raise_condition
875025 T@8: | | | | | | | | | | | | >*MEM_ROOT::AllocSlow
875026 T@8: | | | | | | | | | | | | | enter: root: 0x11e80c728
875027 T@8: | | | | | | | | | | | | | >*MEM_ROOT::AllocBlock
875028 T@8: | | | | | | | | | | | | | <*MEM_ROOT::AllocBlock
875029 T@8: | | | | | | | | | | | | <*MEM_ROOT::AllocSlow
875030 T@8: | | | | | | | | | | | <*THD::raise_condition
875031 T@8: | | | | | | | | | | <push_warning
875032 T@8: | | | | | | | | | <push_warning_printf
875033 T@8: | | | | | | | | | info: add_key_field for field group_id
875034 T@8: | | | | | | | | | >push_warning_printf
875035 T@8: | | | | | | | | | | enter: warning: 1739
875036 T@8: | | | | | | | | | | >push_warning
875037 T@8: | | | | | | | | | | | enter: code: 1739, msg: Cannot use ref access on index 'ix_groupid_memberid' due to type or collation conversion on field 'group_id'
875038 T@8: | | | | | | | | | | | >*THD::raise_condition
875039 T@8: | | | | | | | | | | | <*THD::raise_condition
875040 T@8: | | | | | | | | | | <push_warning
875041 T@8: | | | | | | | | | <push_warning_printf
...
875064 T@8: | | | | | | | | | | >test_quick_select
875065 T@8: | | | | | | | | | | | enter: keys_to_use: 2 prev_tables: 0
875066 T@8: | | | | | | | | | | | opt: range_analysis: starting struct
875067 T@8: | | | | | | | | | | | opt: table_scan: starting struct
875068 T@8: | | | | | | | | | | | opt: rows: 15
875069 T@8: | | | | | | | | | | | opt: cost: 4.6
875070 T@8: | | | | | | | | | | | opt: table_scan: ending struct
875071 T@8: | | | | | | | | | | | opt: potential_range_indexes: starting struct
## --> test_quick_select() 함수는 다양한 범위에서 키를 사용할 수 있는지 테스트하고, 테이블/인덱스 스캔보다 저렴하다고 예상되는 가장 효율적인 QUICK 접근 방법(범위, 인덱스 병합 등)을 생성함
## --> 이 호출 후, 호출자(caller)는 QEP_TAB::set_range_scan()을 호출하고 적절한 경우 tab->type()을 업데이트하여 반환된 QUICK을 실제로 사용하기로 결정할 수 있음.
...
## --> range 조건에 대한 설정 시작
87587 T@8: | | | | | | | | | | | opt: setup_range_conditions: starting struct
875088 T@8: | | | | | | | | | | | >*get_mm_tree
875089 T@8: | | | | | | | | | | | | >*get_full_func_mm_tree
875090 T@8: | | | | | | | | | | | | | >*get_func_mm_tree
875091 T@8: | | | | | | | | | | | | | | >*get_mm_parts
875092 T@8: | | | | | | | | | | | | | | | >*MEM_ROOT::AllocSlow
875093 T@8: | | | | | | | | | | | | | | | | enter: root: 0x175c0c340
875094 T@8: | | | | | | | | | | | | | | | | >*MEM_ROOT::AllocBlock
875095 T@8: | | | | | | | | | | | | | | | | | >char *PFS_instr_name::str
875096 T@8: | | | | | | | | | | | | | | | | | <char *PFS_instr_name::str
875097 T@8: | | | | | | | | | | | | | | | | <*MEM_ROOT::AllocBlock
875098 T@8: | | | | | | | | | | | | | | | <*MEM_ROOT::AllocSlow
875099 T@8: | | | | | | | | | | | | | | | >*get_mm_leaf
875100 T@8: | | | | | | | | | | | | | | | | >Item::save_in_field_no_warnings
875101 T@8: | | | | | | | | | | | | | | | | | >Item::save_in_field
875102 T@8: | | | | | | | | | | | | | | | | | <Item::save_in_field
875103 T@8: | | | | | | | | | | | | | | | | <Item::save_in_field_no_warnings
875104 T@8: | | | | | | | | | | | | | | | <*get_mm_leaf
875105 T@8: | | | | | | | | | | | | | | <*get_mm_parts
875106 T@8: | | | | | | | | | | | | | | >*tree_and
875107 T@8: | | | | | | | | | | | | | | <*tree_and
875108 T@8: | | | | | | | | | | | | | | >*get_mm_parts
875109 T@8: | | | | | | | | | | | | | | | >*get_mm_leaf
875110 T@8: | | | | | | | | | | | | | | | | >Item::save_in_field_no_warnings
875111 T@8: | | | | | | | | | | | | | | | | | >Item::save_in_field
875112 T@8: | | | | | | | | | | | | | | | | | <Item::save_in_field
875113 T@8: | | | | | | | | | | | | | | | | <Item::save_in_field_no_warnings
875114 T@8: | | | | | | | | | | | | | | | <*get_mm_leaf
875115 T@8: | | | | | | | | | | | | | | <*get_mm_parts
875116 T@8: | | | | | | | | | | | | | | >*tree_and
875117 T@8: | | | | | | | | | | | | | | | info: sel_tree: 0x12a09bfc8, type=2, tree1->keys[0(1)]: (group_id = '10000')
875118 T@8: | | | | | | | | | | | | | | | info: sel_tree: 0x12a09c180, type=2, tree2->keys[0(1)]: (member_id = 'aaa123bbb')
## --> AND 조건으로 생성된 첫 번째 트리
875119 T@8: | | | | | | | | | | | | | | <*tree_and
875120 T@8: | | | | | | | | | | | | | | >*tree_or
875121 T@8: | | | | | | | | | | | | | | <*tree_or
875122 T@8: | | | | | | | | | | | | | | >*get_mm_parts
875123 T@8: | | | | | | | | | | | | | | | >*get_mm_leaf
875124 T@8: | | | | | | | | | | | | | | | | >Item::save_in_field_no_warnings
875125 T@8: | | | | | | | | | | | | | | | | | >Item::save_in_field
875126 T@8: | | | | | | | | | | | | | | | | | <Item::save_in_field
875127 T@8: | | | | | | | | | | | | | | | | <Item::save_in_field_no_warnings
875128 T@8: | | | | | | | | | | | | | | | <*get_mm_leaf
875129 T@8: | | | | | | | | | | | | | | <*get_mm_parts
875130 T@8: | | | | | | | | | | | | | | >*tree_and
875131 T@8: | | | | | | | | | | | | | | <*tree_and
875132 T@8: | | | | | | | | | | | | | | >*get_mm_parts
875133 T@8: | | | | | | | | | | | | | | | >*get_mm_leaf
875134 T@8: | | | | | | | | | | | | | | | | >Item::save_in_field_no_warnings
875135 T@8: | | | | | | | | | | | | | | | | | >Item::save_in_field
875136 T@8: | | | | | | | | | | | | | | | | | <Item::save_in_field
875137 T@8: | | | | | | | | | | | | | | | | <Item::save_in_field_no_warnings
875138 T@8: | | | | | | | | | | | | | | | <*get_mm_leaf
875139 T@8: | | | | | | | | | | | | | | <*get_mm_parts
875140 T@8: | | | | | | | | | | | | | | >*tree_and
875141 T@8: | | | | | | | | | | | | | | | info: sel_tree: 0x12a09c338, type=2, tree1->keys[0(1)]: (group_id = '10000')
875142 T@8: | | | | | | | | | | | | | | | info: sel_tree: 0x12a09c4f0, type=2, tree2->keys[0(1)]: (member_id = '37ce484a9e')
## --> AND 조건으로 생성된 두 번째 트리
875143 T@8: | | | | | | | | | | | | | | <*tree_and
875144 T@8: | | | | | | | | | | | | | | >*tree_or
875145 T@8: | | | | | | | | | | | | | | | >sel_trees_can_be_ored
875146 T@8: | | | | | | | | | | | | | | | | info: sel_tree: 0x12a09c338, type=2, tree1->keys[0(1)]: (group_id = '10000' AND member_id = '37ce484a9e')
875147 T@8: | | | | | | | | | | | | | | | | info: sel_tree: 0x12a09bfc8, type=2, tree2->keys[0(1)]: (group_id = '10000' AND member_id = 'aaa123bbb')
875148 T@8: | | | | | | | | | | | | | | | <sel_trees_can_be_ored
## --> 두 개의 AND 트리가 OR 트리로 생성될 수 있음을 보여줌
875149 T@8: | | | | | | | | | | | | | | <*tree_or
875150 T@8: | | | | | | | | | | | | | <*get_func_mm_tree
875151 T@8: | | | | | | | | | | | | <*get_full_func_mm_tree
875152 T@8: | | | | | | | | | | | | info: sel_tree: 0x12a09c338, type=2, tree_returned->keys[0(1)]: (group_id = '10000' AND member_id = '37ce484a9e') OR (group_id = '10000' AND member_id = 'aaa123bbb')
## --> 결과적으로 선택된 트리는 (? AND ?) OR (? AND ?)
875153 T@8: | | | | | | | | | | | <*get_mm_tree
875154 T@8: | | | | | | | | | | | opt: setup_range_conditions: ending struct
## --> range 조건에 대한 설정 종료
뒤이어지는 트레이스 내용을 미리 확인해도 좋지만, 우선 push_warning_printf() 함수를 호출하는 부분부터 디버깅(트레이스 로깅이 아닌 소스파일 디버깅을 의미)을 시작해나가는 것이 정신 건강에 더 이로울 것이다.
이제부터 디버깅과 트레이스 내용을 오고가며, 함수 호출 순서대로 차례차례 분석을 수행해보자.
MySQL Server Source Debugging
MySQL 소스 디버깅을 하기에 앞서, push_warning_printf() 함수가 호출되는 전 과정을, 아래 함수 호출 흐름도로 가볍게 들여다보고 시작하자.
(MySQL 서버의 소스 디버깅을 하는 방법은 블로그 내용을 참고하거나, 사용하는 디버거의 문서 내용을 확인하면 된다.)

원래는 push_warning_printf() 함수 호출부터 디버깅을 시작해서 호출된 함수를 역으로 찾아가는 것이 정석이지만, 이미 그것은 내가 확인했기 때문에 add_key_fields() 함수 호출부터 디버깅을 시작하면 된다.
아래는 add_key_fields() 함수 내에서 Multi IN clause 쿼리에 부합되는 조건문이다. 꽤 복잡하게 설명되어 있지만 전달하고자 하는 핵심 내용은 두 가지이다. 첫 번째는 이 함수의 목적이 rhs(right hand side) 조건 값들이 상수 표현식을 가지고 있는지 확인한다는 것. 두 번째는 range_optimizer가 호출될 수 있도록 하기 위함이라는 것(조건 값이 상수 표현식인지에 따라 내부적으로 const_keys 맵을 업데이트 한다. 그리고 이 값은 이후에 range optimizer를 사용할지 여부를 결정한다). 이 2가지 목적을 가지고 add_key_fields() 함수를 호출한다. 위의 함수 호출 흐름도에서 보면 알겠지만, add_key_fields() 함수 호출 이후에는 add_key_field() 함수를 호출한다.
// add_key_fields 함수
else if (cond_func->functype() == Item_func::IN_FUNC &&
cond_func->key_item()->type() == Item::ROW_ITEM) {
/*
The condition is (column1, column2, ... ) IN ((const1_1, const1_2),
...) and there is an index on (column1, column2, ...)
The code below makes sure that the row constructor on the lhs indeed
contains only column references before calling add_key_field on them.
We can't do a ref access on IN, yet here we are. Why? We need
to run add_key_field() only because it verifies that there are
only constant expressions in the rows on the IN's rhs, see
comment above the call to add_key_field() below.
Actually, We could in theory do a ref access if the IN rhs
contained just a single row, but there is a hack in the parser
causing such IN predicates be parsed as row equalities.
(조건은 (column1, column2, ...) IN ((const1_1, const1_2),...) 이며 (column1, column2, ...)에 대한 인덱스가 존재한다.
아래 코드는 add_key_field를 호출하기 전에 왼쪽 핸드 사이드(LHS)의 행 생성자가 오직 열 참조만을 포함하고 있는지를 확실히 한다.
우리는 IN에 대한 참조(ref) 접근을 할 수 없지만, 여기에는 필요한 이유가 있다.
왜냐하면 add_key_field()는 IN의 오른쪽 핸드 사이드(RHS)에 있는 행들이 오직 상수 표현식만 포함하고 있는지 검증하기 때문이다.
이에 대한 설명은 add_key_field() 호출 위의 주석에서 확인할 수 있다.
실제로, 이론적으로는 IN의 RHS가 단 하나의 행만을 포함한다면 참조 접근을 할 수 있겠지만, 파서에 있는 특정 해킹 때문에 이러한 IN 조건이 행 동등성으로 파싱되게 한다.)
*/
Item_row *lhs_row = static_cast<Item_row *>(cond_func->key_item());
if (is_row_of_local_columns(lhs_row)) {
for (uint i = 0; i < lhs_row->cols(); ++i) { ## --> 좌항의 컬럼 개수만큼 반복 ex) (group_id, member_id) in (('10000', 'aaa123bbb'), ('10000', '37ce484a9e'))
Item *const lhs_item = lhs_row->element_index(i)->real_item();
assert(lhs_item->type() == Item::FIELD_ITEM); ## --> 테이블 컬럼?인지 체크
Item_field *const lhs_column = static_cast<Item_field *>(lhs_item);
// j goes from 1 since arguments()[0] is the lhs of IN.
for (uint j = 1; j < cond_func->argument_count(); ++j) {
// Here we pick out the i:th column in the j:th row.
Item *rhs_item = cond_func->arguments()[j];
assert(rhs_item->type() == Item::ROW_ITEM); ## --> 행 값인지? 체크
Item_row *rhs_row = static_cast<Item_row *>(rhs_item);
assert(rhs_row->cols() == lhs_row->cols()); ## --> 좌변의 컬럼 개수와 우변의 컬럼 개수가 동일한지 체크
Item **rhs_expr_ptr = rhs_row->addr(i);
/*
add_key_field() will write a Key_field on each call
here, but we don't care, it will never be used. We only
call it for the side effect: update JOIN_TAB::const_keys
so the range optimizer can be invoked. We pass a
scrap buffer and pointer here.
(add_key_field()는 여기서 호출될 때마다 Key_field를 작성하지만, 우리는 그것이 사용되지 않을 것이므로 신경 쓰지 않는다.
우리가 이 함수를 호출하는 유일한 이유는 부수 효과 때문이다:
JOIN_TAB::const_keys를 업데이트해서 범위 최적화기(range optimizer)가 호출될 수 있도록 하기 위함이다.
우리는 여기에 폐기물 버퍼와 포인터를 전달한다.)
*/
Key_field scrap_key_field = **key_fields;
Key_field *scrap_key_field_ptr = &scrap_key_field;
if (add_key_field(thd, &scrap_key_field_ptr, *and_level,
cond_func, lhs_column,
true, // eq_func
rhs_expr_ptr,
1, // Number of expressions: one
usable_tables,
nullptr)) // sargables
return true;
// The pointer is not supposed to increase by more than one.
assert(scrap_key_field_ptr <= &scrap_key_field + 1);
}
}
}
}
아래는 이어서 호출되는 add_key_field() 함수의 일부분이다. 아래 코드에서 lhs(left hand side)와 rhs의 값을 비교할 수 있는지 체크하는데, 이게 무슨 말인가 하면, IN 조건을 기준으로 왼쪽 필드의 콜레이션과 오른쪽 값의 콜레이션을 서로 비교할 수 있는지 체크한다는 말이다.
// add_key_field 함수
...
...
if (!comparable_in_index(cond, field, Field::itRAW, cond->functype(),
*value) ||
(field->cmp_type() == STRING_RESULT &&
field->match_collation_to_optimize_range() &&
field->charset() != cond->compare_collation())) {
warn_index_not_applicable(stat->join()->thd, field, possible_keys);
return false;
}
그 비교를 comparable_in_index() 함수에서 수행한다. 아래는 해당 함수의 코드 일부분인데,
// comparable_in_index 함수(range_optimizer.cc)
...
...
// 필드 타입이 STRING_RESULT인지 체크
if ((field->result_type() == STRING_RESULT &&
// 콜레이션 범위 최적화에 적합한지 체크(문자 콜레이션으로 레인지 작업이 가능한지 확인하는 듯)
field->match_collation_to_optimize_range() &&
// RAW 형태인지, MBR 형태인지 체크
value->result_type() == STRING_RESULT && itype == Field::itRAW &&
// 필드의 콜레이션과 조건값의 콜레이션이 일치하는지 체크
field->charset() != cond_func->compare_collation() &&
// equal 조건이 아닌 IN 조건이기 때문에 IN_FUNC
!((comp_type == Item_func::EQUAL_FUNC ||
comp_type == Item_func::EQ_FUNC) &&
cond_func->compare_collation()->state & MY_CS_BINSORT)))
// 콜레이션을 비교할 수 없는 경우 false 반환
return false;
다음의 조건문을 눈여겨 보자. 이 조건이 필드의 콜레이션과 조건값의 콜레이션이 일치하는지 체크하는 부분이다.
field->charset() != cond_func->compare_collation()
그럼 이제 디버거로 두 개의 피연산자 값을 확인해보자. 다른 값들은 무시하고 csname, m_coll_name, comment 3개의 값만 확인하면 된다. 확인해보면, 필드의 캐릭터셋, 콜레이션은 utf8mb4, utf8mb4_0900_ai_ci인 반면에, 조건 값의 캐릭터셋, 콜레이션은 binary, binary인 것을 확인할 수 있다.
바로 여기가 explain에서 오류가 발생하게 되는 이유의 근원지이다.
// field->charset()
(lldb) p *field->charset()
(const CHARSET_INFO) {
...
csname = 0x000000010437b5bd "utf8mb4"
m_coll_name = 0x0000000104b269ff "utf8mb4_0900_ai_ci"
comment = 0x0000000104ce64e2 "UTF-8 Unicode"
...
}
// cond_func->compare_collation()
(lldb) p *cond_func->compare_collation()
(const CHARSET_INFO) {
...
csname = 0x000000010437b5c5 "binary"
m_coll_name = 0x000000010437b5c5 "binary"
comment = 0x0000000104ce31e2 "Binary pseudo charset"
...
}
필드와 조건 값의 콜레이션을 비교할 수 없기 때문에 comparable_in_index() 함수에서 false를 반환하게 되고, 아래 조건문에 부합됨에 따라 이어서 warn_index_not_applicable() 함수를 호출하게 된다.
// add_key_field 함수
...
...
if (!comparable_in_index(cond, field, Field::itRAW, cond->functype(),
*value) ||
(field->cmp_type() == STRING_RESULT &&
field->match_collation_to_optimize_range() &&
field->charset() != cond->compare_collation())) {
warn_index_not_applicable(stat->join()->thd, field, possible_keys);
return false;
}
그리고 warn_index_not_applicable() 함수 내부에서 다시 push_warning_printf() 함수를 호출하고, 결국 실행 계획에 오류가 출력되는 것이다.
// warn_index_not_applicable() 함수
static void warn_index_not_applicable(THD *thd, const Field *field,
const Key_map cant_use_index) {
Functional_index_error_handler functional_index_error_handler(field, thd);
// explain으로 쿼리를 수행하는 경우에만 경고문구 출력
if (thd->lex->is_explain() ||
thd->variables.option_bits & OPTION_SAFE_UPDATES)
for (uint j = 0; j < field->table->s->keys; j++)
if (cant_use_index.is_set(j))
// 옵티마이저 트레이스에서 보면 push_warning_printf() 함수에서 오류가 출력되는 것을 확인할 수 있음
push_warning_printf(thd, Sql_condition::SL_WARNING,
ER_WARN_INDEX_NOT_APPLICABLE,
ER_THD(thd, ER_WARN_INDEX_NOT_APPLICABLE), "ref",
// 사용할 수 없는 인덱스에 대한 정보를 넘겨줌
field->table->key_info[j].name, field->field_name);
}
이제부터는 오류 출력 이후에 수행되는 과정을 살펴볼 것이다. ref 액세스 방식을 사용할 수 없어서 오류가 발생한 상황인데, 어떻게 인덱스 레인지 스캔을 하는걸까 라는 의문이 들었다면 아주 나이스한 상황이다.
이번에도 먼저 함수 호출 흐름도를 가볍게 살펴보고 진행한다.
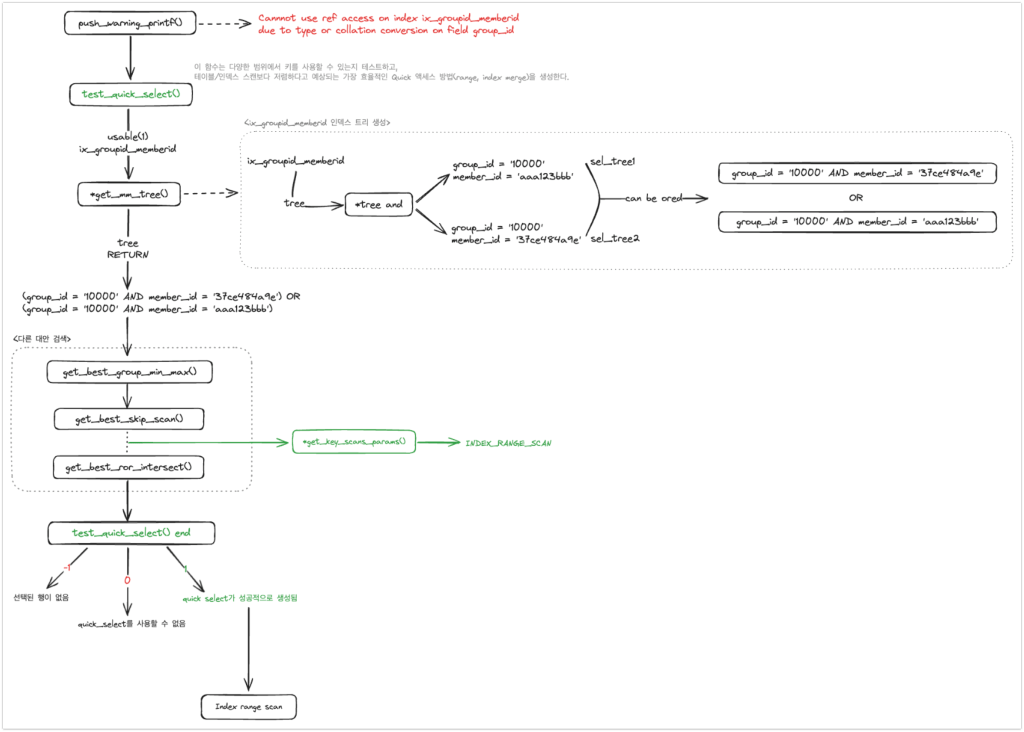
전체 흐름을 간단하게 설명하면, 먼저 test_quick_select() 함수를 호출하고, 그 안에서 다시 get_mm_tree() 함수를 호출한다. get_mm_tree() 함수에서는 쿼리에 사용 가능한 인덱스에 대해서 트리를 생성하는데, 여기에서는 Row constructor 방식의 쿼리 조건이 AND/OR 방식으로 변환되어 트리가 생성된다. 즉 일반적인 IN 조건의 쿼리로 트리를 생성해서 해당 트리로 접근할 수 있는 가장 효율적인 액세스 방식을 선택하여 쿼리를 수행하게 된다.
오류 출력 이후에 가장 먼저 호출되는 함수는 test_quick_select() 함수인데, 함수의 이름에 test가 들어가서 테스트성의 함수처럼 보이지만 사실은 아주 중요한 역할을 하는 함수이다. 위에서 말한 것처럼, 아래 get_mm_tree() 함수에서 AND/OR 트리를 생성한 다음,
// test_quick_select() 함수
SEL_TREE *tree = nullptr;
if (cond) {
{
Opt_trace_array trace_setup_cond(trace, "setup_range_conditions");
tree = get_mm_tree(thd, ¶m, prev_tables | INNER_TABLE_BIT,
read_tables | INNER_TABLE_BIT,
table->pos_in_table_list->map(),
/*remove_jump_scans=*/true, cond);
}
if (tree) {
if (tree->type == SEL_TREE::IMPOSSIBLE) {
trace_range.add("impossible_range", true);
cost_est.reset();
cost_est.add_io(static_cast<double>(HA_POS_ERROR));
return -1;
}
/*
If the tree can't be used for range scans, proceed anyway, as we
can construct a group-min-max quick select
*/
if (tree->type != SEL_TREE::KEY) {
trace_range.add("range_scan_possible", false);
if (tree->type == SEL_TREE::ALWAYS)
trace_range.add_alnum("cause", "condition_always_true");
tree = nullptr;
}
}
}
아래 get_key_scans_params() 함수에서 인덱스 레인지 스캔(INDEX_RANGE_SCAN)을 가장 효율적인 액세스 방식으로 채택한다.
(이어서 수행되는 최적화 함수들이 있지만 Multi IN clause의 경우에는 해당되지 않는다.)
// test_quick_select() 함수에서 get_key_scans_params() 함수를 통해서 best_path로 인덱스 레인지 스캔(INDEX_RANGE_SCAN) 선택
{
/*
Calculate cost of single index range scan and possible
intersections of these
*/
Opt_trace_object trace_range_alt(trace, "analyzing_range_alternatives",
Opt_trace_context::RANGE_OPTIMIZER);
AccessPath *range_path = get_key_scans_params(
thd, ¶m, tree, false, true, interesting_order,
skip_records_in_range, best_cost, needed_reg);
/* Get best 'range' plan and prepare data for making other plans */
if (range_path) {
best_path = range_path;
best_cost = best_path->cost;
}
/*
Simultaneous key scans and row deletes on several handler
objects are not allowed so don't use ROR-intersection for
table deletes. Also, ROR-intersection cannot return rows in
descending order
*/
if ((thd->lex->sql_command != SQLCOM_DELETE) &&
(index_merge_allowed ||
hint_table_state(thd, param.table->pos_in_table_list,
INDEX_MERGE_HINT_ENUM, 0)) &&
interesting_order != ORDER_DESC) {
/*
Get best non-covering ROR-intersection plan and prepare data for
building covering ROR-intersection.
*/
AccessPath *rori_path = get_best_ror_intersect(
thd, ¶m, table, index_merge_intersect_allowed, tree,
&needed_fields, best_cost,
/*force_index_merge_result=*/true, /*reuse_handler=*/true);
if (rori_path) {
best_path = rori_path;
best_cost = best_path->cost;
}
}
}
test_quick_select() 함수의 반환 타입은 Integer인데, 효율적이면서도 저렴한 액세스 방식을 찾았을 경우 1을 반환하게 된다. 디버거에서 test_quick_select() 호출 이후에 AccessPath 유형을 확인해보면, range_scan 유형이 INDEX_RANGE_SCAN으로 설정된 것을 확인할 수 있다.
(참고로 AccessPath의 type은 access_path.h 파일에 enum 유형으로 총 45개가 정의되어 있다.)
// test_quick_select를 빠져나와서
6164 int error = test_quick_select(
6165 thd, thd->mem_root, &temp_mem_root, keys_to_use, 0,
6166 0, // empty table_map
6167 limit,
6168 false, // don't force quick range
6169 ORDER_NOT_RELEVANT, tab->table(), tab->skip_records_in_range(),
6170 condition, &tab->needed_reg, tab->table()->force_index,
6171 tab->join()->query_block, &range_scan);
// range scan 사용 설정
6172 tab->set_range_scan(range_scan);
6173
6174 if (error == 1) return range_scan->num_output_rows();
6175 if (error == -1) {
6176 tl->table->reginfo.impossible_range = true;
6177 return 0;
6178 }
(lldb) p error
// test_quick_select() 함수의 반환값 = 1
(int) 1
(lldb) p range_scan.type
// 액세스 방식은 인덱스 레인지 스캔
(AccessPath::Type) INDEX_RANGE_SCAN
(lldb) p range_scan->num_output_rows()
// 레인지 스캔으로 출력된 행수 6개
(double) 6
최종적으로 옵티마이저는 인덱스 레인지 스캔을 최적의 액세스 방식으로 선택하고 실행 계획을 생성한다.
Thread memory usage
이번에는 Multi IN 조건과 general IN 조건을 메모리 사용 관점에서 비교해보자.
메모리 사용량 측정은 다음과 같이 진행하였다.
- 쿼리 수행 전 Multi IN clause 쿼리를 수행하는 스레드의 메모리 사용량 측정
- Multi IN clause 쿼리 수행
- Multi IN clause 쿼리를 수행하는 스레드의 메모리 사용량 측정
- 쿼리 수행 전 General IN clause 쿼리를 수행하는 스레드의 메모리 사용량 측정
- General IN clause 쿼리 수행
- General IN clause 쿼리를 수행하는 스레드의 메모리 사용량 측정
- Multi IN clause와 General IN clause의 순서를 바꾸어 1~9번까지 반복
아래는 테스트에 사용된 테이블 및 쿼리이다.
// 프로세스 id 조회
mysql>SELECT thread_id FROM performance_schema.threads WHERE processlist_id = <process_id>
// 메모리 할당량을 계산하기 위한 중간 테이블
mysql>CREATE TABLE `ps_memory_diff` (
`seq` int NOT NULL,
`event_name` varchar(100) NOT NULL,
`count_alloc` bigint DEFAULT NULL,
`count_free` bigint DEFAULT NULL,
`SUM_NUMBER_OF_BYTES_ALLOC` bigint DEFAULT NULL,
`SUM_NUMBER_OF_BYTES_FREE` bigint DEFAULT NULL,
PRIMARY KEY (`seq`,`event_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
// 쿼리 수행 전 Init 데이터
mysql> insert into test.ps_memory_diff SELECT 1, event_name, count_alloc, count_free, SUM_NUMBER_OF_BYTES_ALLOC, SUM_NUMBER_OF_BYTES_FREE from performance_schema.memory_summary_by_thread_by_event_name where event_name like '%memory%' and thread_id = <thread_id> and count_alloc <> 0 and count_free <> 0 and SUM_NUMBER_OF_BYTES_ALLOC <> 0 and SUM_NUMBER_OF_BYTES_FREE <> 0;
// Multi IN 쿼리 수행 후 메모리 사용량 데이터
mysql> insert into test.ps_memory_diff SELECT 2, event_name, count_alloc, count_free, SUM_NUMBER_OF_BYTES_ALLOC, SUM_NUMBER_OF_BYTES_FREE from performance_schema.memory_summary_by_thread_by_event_name where event_name like '%memory%' and thread_id = <thread_id> and count_alloc <> 0 and count_free <> 0 and SUM_NUMBER_OF_BYTES_ALLOC <> 0 and SUM_NUMBER_OF_BYTES_FREE <> 0;
// General IN 쿼리 수행 후 메모리 사용량 데이터
mysql> insert into test.ps_memory_diff SELECT 3, event_name, count_alloc, count_free, SUM_NUMBER_OF_BYTES_ALLOC, SUM_NUMBER_OF_BYTES_FREE from performance_schema.memory_summary_by_thread_by_event_name where event_name like '%memory%' and thread_id = <thread_id> and count_alloc <> 0 and count_free <> 0 and SUM_NUMBER_OF_BYTES_ALLOC <> 0 and SUM_NUMBER_OF_BYTES_FREE <> 0;
// Multi IN 쿼리와 General IN 쿼리의 메모리 할댱량 계산
mysql>select multi.event_name,
(multi.count_alloc - init.count_alloc) as multi_count_alloc,
(gen.count_alloc - multi.count_alloc) as gen_count_alloc,
(multi.SUM_NUMBER_OF_BYTES_ALLOC - init.SUM_NUMBER_OF_BYTES_ALLOC) as multi_SUM_NUMBER_OF_BYTES_ALLOC,
(gen.SUM_NUMBER_OF_BYTES_ALLOC - multi.SUM_NUMBER_OF_BYTES_ALLOC) as gen_SUM_NUMBER_OF_BYTES_ALLOC
from test.ps_memory_diff as multi
join test.ps_memory_diff as init on multi.event_name = init.event_name and init.seq = 1
join test.ps_memory_diff as gen on multi.event_name = gen.event_name and gen.seq = 3
where multi.seq = 2
and (multi.SUM_NUMBER_OF_BYTES_ALLOC - init.SUM_NUMBER_OF_BYTES_ALLOC) <> 0
and (gen.SUM_NUMBER_OF_BYTES_ALLOC - multi.SUM_NUMBER_OF_BYTES_ALLOC) <> 0
다음은 테스트 쿼리를 통해 Multi IN 쿼리와 General IN 쿼리의 메모리 할당량을 비교한 결과이다.
테스트 결과를 보면 General IN 조건의 쿼리가 memory/sql/THD::main_mem_root 이벤트에서 더 많은 메모리를 할당받는 것을 확인할 수 있다. THD::main_mem_root 이벤트는 쿼리 영역과 같은 목적으로 사용되는 메인 메모리 루트를 나타낸다.
(아레나 기반의 메모리 할당 방식을 사용하여 여러 개의 작은 메모리 할당을 처리하기 위해 한 번에 큰 메모리 블록을 할당한다. 그리고 해당 블록 내에서 필요한 만큼의 메모리를 작은 조각으로 할당한다. 이러한 할당 방식은 개별적인 메모리 할당 요청에 대해 매번 운영 체제에 할당 요청을 보내지 않아도 되기 때문에 개별 할당보다 상대적으로 빠르다. 그리고 할당된 전체 블록을 한 번에 해제할 수 있기 때문에 개별 할당에 대한 추적과 해제를 신경 쓸 필요가 없다. 이는 곧 메모리 누수를 방지할 수 있다.)
// 테스트 쿼리
// Multi IN
SELECT * FROM test WHERE (group_id, member_id) in (('10000', 'aaa123bbb'), ('10000', '37ce484a9e'));
// General IN
SELECT * FROM test WHERE (group_id = '10000' and member_id = 'aaa123bbb') OR (group_id = '10000' and member_id = '37ce484a9e');
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| event_name | multi_count_alloc | gen_count_alloc | multi_SUM_NUMBER_OF_BYTES_ALLOC | gen_SUM_NUMBER_OF_BYTES_ALLOC |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| memory/innodb/memory | 2 | 2 | 752 | 752 |
| memory/mysqld_openssl/openssl_malloc | 2 | 2 | 216 | 216 |
| memory/sql/MYSQL_LOCK | 1 | 1 | 64 | 64 |
| memory/sql/String::value | 1 | 1 | 56 | 56 |
| memory/sql/test_quick_select | 1 | 1 | 4144 | 4144 |
| memory/sql/THD::main_mem_root | 1 | 3 | 27696 | 39056 |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
아래는 테스트 쿼리에서 IN 조건 개수를 늘려가며 메모리 사용량을 확인한 결과이다.
(차이가 발생하지 않는 이벤트는 제외하였다)
// 2개 IN 조건
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| event_name | multi_count_alloc | gen_count_alloc | multi_SUM_NUMBER_OF_BYTES_ALLOC | gen_SUM_NUMBER_OF_BYTES_ALLOC |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| memory/sql/THD::main_mem_root | 1 | 3 | 27696 | 39056 |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
// 100개 IN 조건
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| event_name | multi_count_alloc | gen_count_alloc | multi_SUM_NUMBER_OF_BYTES_ALLOC | gen_SUM_NUMBER_OF_BYTES_ALLOC |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| memory/sql/THD::main_mem_root | 7 | 10 | 263888 | 928880 |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
// 200개 IN 조건
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| event_name | multi_count_alloc | gen_count_alloc | multi_SUM_NUMBER_OF_BYTES_ALLOC | gen_SUM_NUMBER_OF_BYTES_ALLOC |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| memory/sql/THD::main_mem_root | 9 | 11 | 613904 | 1403656 |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
// 500개 IN 조건
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| event_name | multi_count_alloc | gen_count_alloc | multi_SUM_NUMBER_OF_BYTES_ALLOC | gen_SUM_NUMBER_OF_BYTES_ALLOC |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
| memory/sql/THD::main_mem_root | 11 | 14 | 1405448 | 4799336 |
+--------------------------------------+-------------------+-----------------+---------------------------------+-------------------------------+
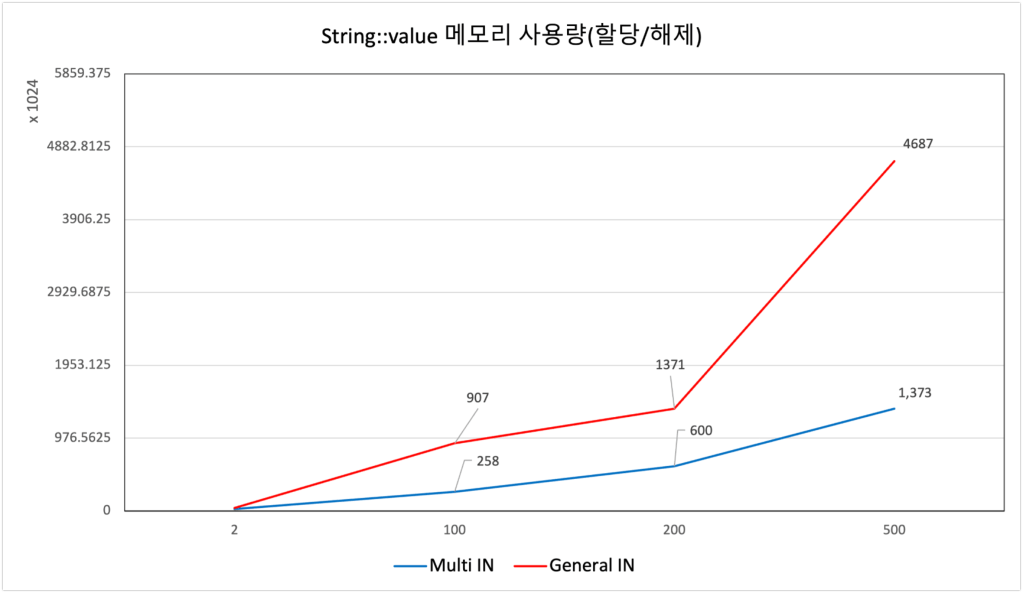
아래 그래프에서 x축은 WHERE절의 조건 개수이고, y축은 memory/sql/THD::main_mem_root 이벤트의 메모리 할당량이다. WHERE절 조건 개수를 늘려갈수록(2, 100, 200, 500), THD::main_mem_root 이벤트 메모리 할당량 또한 증가하는 것을 확인할 수 있다.
WHERE절 조건이 500개일 때, 초당 1000씩 유입되는 DB 서버가 존재한다면 동시에 최대 할당 받아야 하는 메모리 공간은 General IN의 경우 4,799,336 byte * 1,000 = 4.47GB 이며, Multi IN의 경우 1,405,448 byte * 1,000 = 1.3GB 이다.
하지만 여기서 잘못 결론 내리면 안되는 것은, 이 메모리 할당량이 Multi IN 조건과 General IN 조건에 따라 달라지지는 않는다는 것이다.
아래 쿼리들은 모두 동일한 실행계획과 오퍼레이션이 발생하는 쿼리이다. 3개의 쿼리 패턴 중 memory/sql/THD::main_mem_root 이벤트에 가장 많은 메모리가 할당되는 쿼리 패턴은 1번이다. 1번 쿼리의 WHERE절이 가장 긴 문자열을 보유하고 있기 때문에 총체적인 쿼리 비용이 동일하다면 가장 많은 메모리를 할당받게 된다.
// Query 패턴 1
SELECT * FROM test WHERE (a=1 AND b=1) OR (a=1 AND b=2) OR (a=1 AND b=3) OR (a=1 AND b=4) OR (a=2 AND b=1) OR (a=2 AND b=2) OR (a=2 AND b=3)
// Query 패턴 2
SELECT * FROM test WHERE (a, b) IN ((1, 1), (1, 2), (1, 3), (1, 4), (2, 1), (2, 2), (2, 3))
// Query 패턴 3
SELECT * FROM test WHERE (a IN (1, 2) AND b = 1) OR (a IN (1, 2) AND b = 2) OR (a IN (1, 2) AND b = 3) OR (a IN (1) AND b = 4)
다시 말하면 General IN, Multi IN 조건에 따라 메모리 할당량이 달라지는 것이 아니고, 가장 긴 문자열 쿼리가 가장 많은 메모리를 할당받는 것이다.
그래서 현재 수행되는 쿼리가 위와 같이 3개의 쿼리 패턴으로 모두 변경 가능하다면 다음과 같은 조건에 따라 쿼리를 수정하는 것이 좋겠다.
- 쿼리 패턴 1은 어떠한 경우에도 좋은 것이 없다.
- 조건 값(a 또는 b)에 문자열이 포함되어 있지 않다면 Row Constructor 방식의 쿼리 패턴 2가 가장 좋다.
SELECT * FROM test WHERE (a, b) IN ((1, 1), (1, 2), (1, 3), (1, 4), (2, 1), (2, 2), (2, 3))
- 조건 값(a 또는 b)에 문자열이 포함되어 있으면서, 문자열이 아닌 조건(a 또는 b)이 중복되지 않는 값이라면 쿼리 패턴 3이 가장 좋다.
SELECT * FROM test WHERE (a IN (1,2,3,4,5,6,7,8,9,10) AND b = 'AAAABBBBCCCC') OR (a IN (1,2,3,4,5,6,7,8,9,10) AND b = 'ZZZZXXXXYYYY')
Conclusion
Row constructor 방식의 Multi IN 조건은 lhs(left hand side)의 필드 타입 콜레이션과 rhs(right hand side)의 조건 값 콜레이션이 다르기 때문에 실행계획(explain)상에서 참조 액세스(ref access)를 사용할 수 없다는 warning이 발생한다.
하지만 warning 이후에 옵티마이저가 테이블/인덱스 풀스캔보다 저렴한 다른 효율적인 액세스 방식을 찾는 작업을 수행한다(test_quick_select() 함수를 호출하면서 시작된다.). 이 과정에서 좀 더 효율적인 액세스 방식(이 경우에는 INDEX_RANGE_SCAN)을 찾으면, 옵티마이저는 테이블/인덱스 풀스캔이 아니라 다른 액세스 방식을 사용한다.
결과적으로 Multi IN 조건을 사용해서 쿼리를 수행하여도 test_quick_select() 함수에 의해 내부적으로 AND/OR 방식의 트리가 생성되고, 해당 트리로 접근할 수 있는 가장 효율적인 액세스 방식을 선택하여 쿼리를 수행하게 된다.
하지만 IN 조건 방식과는 관계없이 쿼리문 명령 자체에 더 많은 문자열을 보유하게 되면 memory/sql/THD::main_mem_root 이벤트에서 더 많은 메모리 공간을 사용한다(Aurora MySQL에서만 발생). WHERE절 조건 값이 몇 백개 이상 사용된다면 할당받아야 하는 메모리 공간은 점점 더 커지게 된다. 하나의 쿼리문에 대해서 동일한 쿼리 비용과 결과를 보장하는 여러 쿼리 패턴들(위 쿼리의 경우)이 존재하기 때문에 가능하면 쿼리문 길이를 간단하게 변경하는 것이 메모리 효율 관점에서 더 좋다.

댓글 남기기