
오늘은 2024년 6월 18일(화요일)에 AWS DATA & AI ROADSHOW 2024에서 Aurora custom endpoint와 AutoScaling 활용 사례에 대해서 발표한 내용을 공유해보려고 한다.
30분 정도의 발표 시간동안 분명 내용을 놓치신 분들도 계셨을 것이고, 이해가 되지 않는 분들도 계셨을 것이고, 피치 못할 사정으로 참석하지 못한 분들도 계실 것이다. 그래서 좀 더 깔끔히 정리된 내용으로 공유를 드리고자 한다.
목차는 다음과 같다.
- Aurora endpoint 종류
- Custom endpoint 활용 사례
- Custom endpoint의 제한 사항
- Custom endpoint를 위한 Auto Scaling 적용 및 제한
- Auto Scaling 알람 & 모니터링
(1) Aurora endpoint 종류에서는,
Aurora endpoint의 종류는 총 4가지가 존재한다. 각 Aurora endpoint가 DB 인스턴스를 논리 그룹 단위로 어떻게 분류하고 있는지 살펴본다.
(2) Custom endpoint 활용 사례에서는,
당근에서는 4가지 Aurora endpoint 중에서 Custom endpoint를 Reader DB 인스턴의 사용 목적에 따라 구분해서 사용하고 있는데, 실제로 어떻게 활용하고 있는지를 살펴본다.
(3) Custom endpoitn의 제한 사항에서는,
Custom endpoint에는 자그마한 제한 사항이 존재하는데, 그 부분을 간략하게 살펴본다.
(4) Custom endpoint를 위한 Auto Scaling 적용 및 제한에서는,
급작스러운 트래픽 증가에 대한 자동 대응책으로 Auto Scaling을 Aurora DB 클러스터에 적용해볼 수 있는데, Custom endpoint가 적용된 상황에서 Auto Scaling은 어떻게 적용해야 하는지, 그리고 그 제한점은 무엇이 있을지를 살펴본다.
(5) Auto Scaling 알람 & 모니터링에서는,
Auto Scaling이 동작할 때 알람은 어떻게 받고 있는지, 그리고 모니터링을 어떻게 하고 있는지 살펴본다.

Aurora endpoint 종류
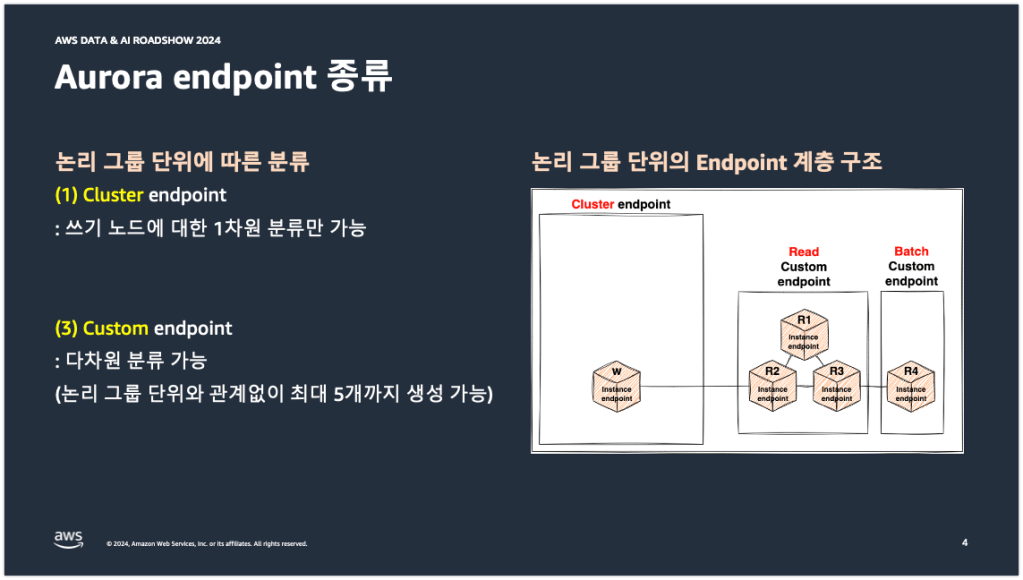
목차에서 설명했듯이 Aurora endpoint의 종류는 총 4가지가 존재한다. Cluster, Reader, Custom, Instance endpoint까지 총 4가지이다.
아래 그림 왼쪽에 적힌 설명은 각 엔드포인트가 무엇인지에 대한 설명을 적어놓은 것이 아니라, 각 엔드포인트가 DB 인스턴스를 논리 그룹 단위로 어떻게 분류하고 있는지에 대한 특징, 차이점을 적어놓은 것이다.
첫 번째 Cluster 엔드포인트. Cluster 엔드포인트는 Writer DB 인스턴스에 대한 엔드포인트를 제공한다. 그래서 쓰기 노드에 대한 1차원적인 분류만 가능하다는 특징을 가지고 있다.
두 번째 Reader 엔드포인트. Reader 엔드포인트는 여러대의 Reader DB 인스턴스에 대한 엔드포인트를 제공하지만, 읽기 노드에 대한 1차원적인 분류만 가능하기 때문에 Cluster 엔드포인트와 동일한 특징을 가지고 있다.
세 번째 Custom 엔드포인트. Custom 엔드포인트는 사용자가 DB 인스턴스의 사용 목적에 따라서 최대 5개까지 논리 그룹핑이 가능하기 때문에 다차원 분류가 가능하다는 특징을 가지고 있다.
네 번째 Instance 엔드포인트. Instance 엔드포인트는 단일 인스턴스에 대한 엔드포인트만을 제공하기 때문에 논리 그룹 단위로는 분류가 불가능하다는 특징을 가지고 있다.
아래 오른쪽 그림은 위에서 설명한 내용을 계층 구조로 나타낸 그림이다. 먼저 1차원적인 분류만 가능한 Cluster와 Reader 엔드포인트는 계층 구조 가장 바깥쪽에 구성되어 있는 것을 확인할 수 있다. 그리고 Custom 엔드포인트는 DB 인스턴스의 사용 목적에 따라서 좀 더 세분성 있는 논리 그룹 단위로 계층 안쪽에 구성되어 있는 것을 확인할 수 있다.

당근에서는 이 4가지 엔드포인트 중에서 Cluster 엔드포인트와 Custom 엔드포인트를 사용하고 있다. Cluster 엔드포인트는 DML, DDL과 같은 작업을 수행할 때 사용하고 있으며, Custom 엔드포인트는 서비스 사용 목적에 따라서 아래의 오른쪽 그림과 같이 Read와 Batch 커스텀 엔드포인트로 나누어 사용하고 있다.
당근 앱 내의 일반적인 서비스 쿼리를 수행할 때는 Read 커스텀 엔드포인트를 사용하고 있으며, 배치나 통계, 빅 쿼리 덤프와 같은 일시성의 쿼리를 수행할 때는 Batch 커스텀 엔드포인트를 사용하고 있다. 이 Read와 Batch 커스텀 엔드포인트에 대한 자세한 내용은 Custom endpoint 활용 사례에서 뒤이어 설명하도록 하겠다.
Custom endpoint 활용 사례
당근의 DB 클러스터 구성은 크게 2가지의 경우로 나뉘어진다. 첫 번째는 2대 이하의 DB 인스턴스인 경우, 두 번째는 3대 이상의 DB 인스턴스인 경우이다. DB 클러스터 구성이 이렇게 2가지의 경우로 나뉘어지기 때문에 위에서 설명한 Read와 Batch 커스텀 엔드포인트도 2가지 경우에 다르게 적용된다.
먼저 2대 이하의 DB 인스턴스에 Read와 Batch 커스텀 엔드포인트를 생성하면, 아래 오른쪽 상단의 그림과 같이 커스텀 엔드포인트가 생성된다. 그리고 3대 이상의 DB 인스턴스에 Read와 Batch 커스텀 엔드포인트를 생성하면, 아래 오른쪽 하단의 그림과 같이 커스텀 엔드포인트가 생성된다.
다시 아래 오른쪽 상단의 그림을 봐보겠다. 2대 이하의 DB 인스턴스의 경우에는 Read와 Batch 커스텀 엔드포인트에 중복된 Reader DB 인스턴스가 구성되어 있는 것을 확인할 수 있다. 이렇게 구성한 이유는 당근에서 2대 이하의 DB 인스턴스는, 신규 서비스나 상대적으로 트래픽이 낮은 서비스에 제공되는 DB 클러스터 구성이다. 그래서 Batch 커스텀 엔드포인트를 위한 별도의 Batch DB 인스턴스가 존재하지 않는다. 그래서 Read와 Batch 커스텀 엔드포인트에 중복된 Reader DB 인스턴스를 구성해놓은 것이다. 하지만 누군가가 이렇게 물을 수도 있다.”중복 구성된 커스텀 엔드포인트를 둘 다 사용하는 것도 아니고, Read 커스텀 엔드포인트를 배치 작업에 사용할 수 있는 것이 아니냐” 라고 말이다. 그런데 이것은 향후 스케일 아웃(Scale-out)을 할 때 개발자분들에게 Transparent한 엔드포인트를 제공하려는 목적이 크다. 투명성 있는 엔드포인트를 제공함으로써 DB 인스턴스 구성이 어떻게 변경되든 개발자는 단 2개(Read custom endpoint & Batch custom endpoint)의 엔드포인트만 알고 있으면 되기 때문이다.
3대 이상의 DB 인스턴스인 경우도 살펴보겠다. 3대 이상의 DB 인스턴스인 경우에는 Batch 커스텀 엔드포인트를 위한 별도의 batch 문자열을 가진 Batch DB 인스턴스가 1대 이상씩 존재를 한다. 그래서 아래 오른쪽 하단의 그림과 같이 Read와 Batch 커스텀 엔드포인트에 서로 중복된 Reader DB 인스턴스가 없이 논리적으로 완벽하게 분리된 형태로 커스텀 엔드포인트가 생성되어 있는 것이다.

그런데 여기서 한 가지 생각해봐야할 것이 있다. 앞서 설명한 커스텀 엔드포인트 구성이 Reader DB 인스턴스의 사용 목적에 따라서, 그리고 DB 클러스터 구성에 따라서 설정해놓았다는 것은 대충 이해했다. 그런데 장애조치나 DB 인스턴스 추가/삭제가 발생하면 어떻게 되는 것일까? 그 때마다 커스텀 엔드포인트가 자동으로 구성되는 것일까? 아니면 매번 수동으로 구성해주어야 하는 것일까?
그래서, 당근에서는 Read와 Batch 커스텀 엔드포인트를 위한 별도의 커스텀 엔드포인트 설정을 따르고 있다.
그전에 이 설정과 관련된 아래 3개의 파라미터가 존재하는데, 아래 그림에서 이 부분을 설명하고 자세한 설명으로 넘어가도록 하겠다. 첫 번째 파라미터는 –endpoint-type 파라미터이다. 이 파라미터 값에는 ANY, READER, WRITER 3개의 값 중에 1가지 값을 설정할 수 있다. AWS 콘솔에서 커스텀 엔드포인트를 생성하면 이 값은 무조건 ANY로 설정된다. READER와 WRITER로 변경하거나 생성하고 싶다면 AWS-CLI나 AWS-SDK를 활용해서 변경하거나 생성해야 한다. 두 번째 파라미터는 –static-members 파라미터이다. 이 파라미터는 내가 커스텀 엔드포인트를 생성할 때 이 DB 인스턴스는 반드시 포함시키고 싶어라는 요구사항이 발생했을 때 사용할 수 있는 파라미터이다. 세 번째 파라미터는 –excluded-members 파라미터이다. 이 파라미터는 –static-members 파라미터와 반대되는 파라미터이며, 내가 커스텀 엔드포인트를 생성할 때 이 DB 인스턴스는 반드시 제외시키고 싶어라는 요구사항이 발생했을 때 사용할 있는 파라미터이다.
추가로 한 가지 더 중요한 내용이 있는데, 이 3개의 파라미터는 파라미터 적용 우선순위를 갖는다는 것이다. 가장 먼저 적용되는 파라미터가 –endpoint-type 파라미터이고, 그 이후에 –static-members 파라미터나 –excluded-members 파라미터가 적용된다. 이게 무슨 말인가 하면, 예를 들어 –endpoint-type에 READER를 설정해놓고, –static-members 파라미터에 Writer Role을 가진 DB 인스턴스를 설정하면, –endpoint-type의 READER가 우선 적용되기 때문에 –static-members에 설정해놓았던 Writer Role을 가진 DB 인스턴스는 최종적으로 커스텀 엔드포인트 구성에서 빠지게 된다.
당근에서는 Read와 Batch 커스텀 엔드포인트를 위한 별도의 커스텀 엔드포인트 설정을 따른다고 설명했었는데 이 별도의 커스텀 엔드포인트 설정에 위에서 설명한 3개의 커스텀 엔드포인트 파라미터와 파라미터 적용 우선순위를 사용한다.
그러면 다음 내용에서 이 3개의 파라미터를 실제로 어떻게 활용하고 있는지를 살펴보도록 하겠다.

아래 그림 하단에 보이는 코드는 당근에서 2대 이하의 DB 인스턴스에 커스텀 엔드포인트를 생성할 때 수행하는 CLI 명령문이다. 2대 이하의 DB 인스턴스는 Read Custom CLI와 Batch Custom CLI에 동일한 파라미터 값을 사용하기 때문에 본 내용에서는 Read Custom CLI로 설명을 진행해보겠다.
Read Custom CLI 코드의 빨간 박스 안에 보면 –endpoint-type 파라미터 값이 READER로 설정되어 있는 것을 확인할 수 있다. 당근에서는 이 파라미터 값에 READER를 고정으로 사용하고 있다. 그 이유는 Read와 Batch 커스텀 엔드포인트가 Reader DB 인스턴스들로 구성되기 때문이다. 그리고 그 아래 보면 –static-members 파라미터에 DB 인스턴스의 Role 관계 없이 Writer DB 인스턴스와 Reader DB 인스턴스가 설정되어 있는 것을 확인할 수 있다.

–static-members 파라미터에 DB 인스턴스의 Role에 관계 없이 2개 DB 인스턴스를 설정해놓는 이유는 장애조치가 발생했을 때 장애조치가 발생하기 이전과 동일한 커스텀 엔드포인트 구성을 가져가기 위함이다. 장애조치가 발생할 때마다 DB 인스턴스의 Role은 계속 변경되기 때문에 –static-members 파라미터에 1개 DB 인스턴스만 설정해놓으면 나중에는 Read와 Batch 커스텀 엔드포인트에 0개의 DB 인스턴스가 구성되어 버린다. 이는 서비스 장애로 이어질 수 있기 때문에 반드시 2개 DB 인스턴스를 설정해두어야 한다.
위에서 설명한 내용들을 정리하면 2대 이하의 DB 인스턴스의 경우에는 장애조치에 대응 가능한 형태로 커스텀 엔드포인트 구성이 자동화 되어 있다.

다음으로, 3대 이상의 DB 인스턴스인 경우도 살펴보겠다. 3대 이상의 DB 인스턴스인 경우에는 앞서 설명했듯이 Batch 커스텀 엔드포인트를 위한 batch 문자열을 가진 DB 인스턴스가 1대 이상씩 존재한다. 그래서 Read Custom CLI와 Batch Custom CLI 명령을 수행할 때 Batch DB 인스턴스만 잘 핸들링 해주면 된다.
먼저 Read Custom CLI의 코드의 빨간 박스를 보면, –endpoint-type 파라미터 값은 당연히 READER이다. 그리고 이번에는 –static-members 파라미터가 아니라 –excluded-member 파라미터가 사용되었고, 그 설정 값으로 Batch DB 인스턴스가 설정되어 있는 것을 확인할 수 있다. 이렇게 설정한 이유는 Read 커스텀 엔드포인트를 생성할 때 Batch DB 인스턴스는 반드시 제외시키고 싶어라는 요구사항이 발생했기 때문이다.
그러면 이 Read 커스텀 엔드포인트에 장애조치 상황을 가정해보도록 하겠다. 장애조치가 발생하면 Read 커스텀 엔드포인트는 항상 Batch DB 인스턴스는 제외되도록 설정되어 있기 때문에 그리고 장애조치 우선순위가 가장 낮기 때문에 Batch DB 인스턴스가 Writer DB 인스턴스로 승격될 일이 없으며, –endpoint-type이 READER이기 때문에 Writer DB 인스턴스가 Read 커스텀 엔드포인트에 구성될 일이 없다. 그리고 이는 DB 인스턴스 추가/삭제에도 동일하게 적용된다.
다음으로 Batch Custom CLI 코드의 빨간 박스를 보면 –endpoint-type 파라미터 값은 당연히 READER이고, 이번에는 excluded-members 파라미터가 아니라 –static-members 파라미터가 사용되었으며 그 값으로 Batch DB 인스턴스가 설정되어 있는 것을 확인할 수 있다. 이렇게 설정한 이유는 Batch 커스텀 엔드포인트를 생성할 때 Batch DB 인스턴스는 반드시 포함시키고 싶어라는 요구사항이 발생했기 때문이다.
이번에도 장애조치 상황을 가정해보도록 하겠다. 장애조치가 발생하면 Batch 커스텀 엔드포인트는 반드시 Batch DB 인스턴스를 포함하기 때문에 Writer DB 인스턴스도, 서비스 읽기 전용의 Reader DB 인스턴스도 Batch 커스텀 엔드포인트에 구성되지 않는다. 그리고 이는 DB 인스턴스 추가/삭제에도 동일하게 적용된다.
정리하면 3대 이상의 DB 인스턴스의 경우에는 장애조치, DB 인스턴스 추가/삭제에 대응 가능한 형태로 커스텀 엔드포인트 구성이 자동화 되어 있다.

그리고 양쪽의 CLI 명령문을 수행하면 아래의 화살표 오른쪽과 같이 커스텀 엔드포인트가 생성된다.

아래는 위에서 설명한 내용들을 하나의 표에 정리한 것이다. 정리 차원에서 간단하게만 설명하면,
– 당근에서는 커스텀 엔드포인트를 사용한다.
– 그리고 Reader DB 인스턴스의 사용 목적에 따라서 Read 커스텀 엔드포인트와 Batch 커스텀 엔드포인트로 나누어 사용한다.
– 당근의 DB 클러스터 구성은 2대 이하의 DB 인스턴스와 3대 이상의 DB 인스턴스인 경우로 나누어진다.
– DB 클러스터 구성이 2가지 경우로 나누어지기 때문에 Read와 Batch 커스텀 엔드포인트도 다르게 적용된다.
– 장애조치, DB 인스턴스 추가/삭제에 대응 가능한 형태로 커스텀 엔드포인트 구성을 자동화 하기 위해 별도의 커스텀 엔드포인트 설정을 따른다.
– 그 설정에는 –endpoint-type, –static-members, –excluded-members 파라미터가 사용된다.
– 그리고 파라미터 적용 우선순위를 사용하고 있다.

Custom endpoint의 제한 사항
다음으로 커스텀 엔드포인트의 자그마한 제한 사항을 이야기해보려고 한다. 위에서 설명했지만 커스텀 엔드포인트는 다차원 분류가 가능하다는 특징을 가지고 있다. 하지만 다차원을 3차원 분류 이상으로 사용하게 되면 엔드포인트에 대한 관리가 굉장히 어려워지게 된다.
아래 상단의 test-db 클러스터는 임의로 3차 분류를 해놓은 상태이고, 하단의 test-db 클러스터는 임의로 2차 분류를 해놓은 상태이다. 즉 상단의 test-db 클러스터는 3차원 분류가 된 상태이고, 하단의 test-db 클러스터는 2차원 분류가 된 상태이다.
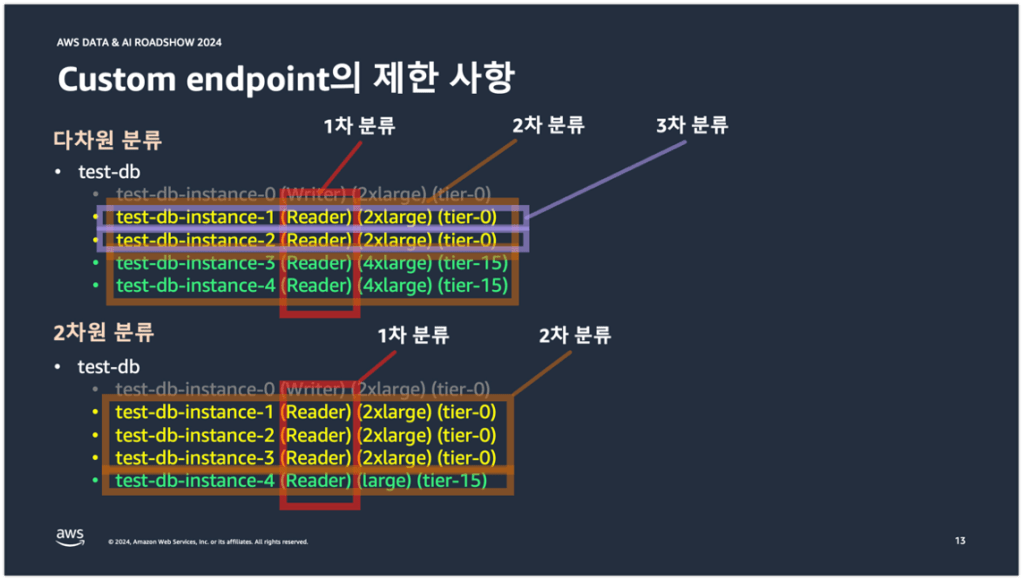
3차원 분류에 커스텀 엔드포인트를 적용하면 아래 화살표 오른쪽과 같이 커스텀 엔드포인트가 생성된다. 먼저 1차 분류는 Reader 엔드포인트로 이미 분류가 된 상태이다. 그다음 2차 분류를 위해 test-db-instance-1,2와 test-db-instance-3,4에 대한 커스텀 엔드포인트 2개를 생성해야 한다. 그다음 3차 분류를 위해 test-db-instance-1과 test-db-instance-2에 대한 커스텀 엔드포인트를 각각 1개씩 총 4개의 커스텀 엔드포인트를 생성해야 한다.

2차원 분류도 살펴보도록 하겠다. 먼저 1차 분류는 Reader 엔드포인트로 분류가 된 상태이고, 2차 분류를 위해서 test-db-instance1,2,3과 test-db-instance-4에 대한 커스텀 엔드포인트 2개를 생성해야 한다.

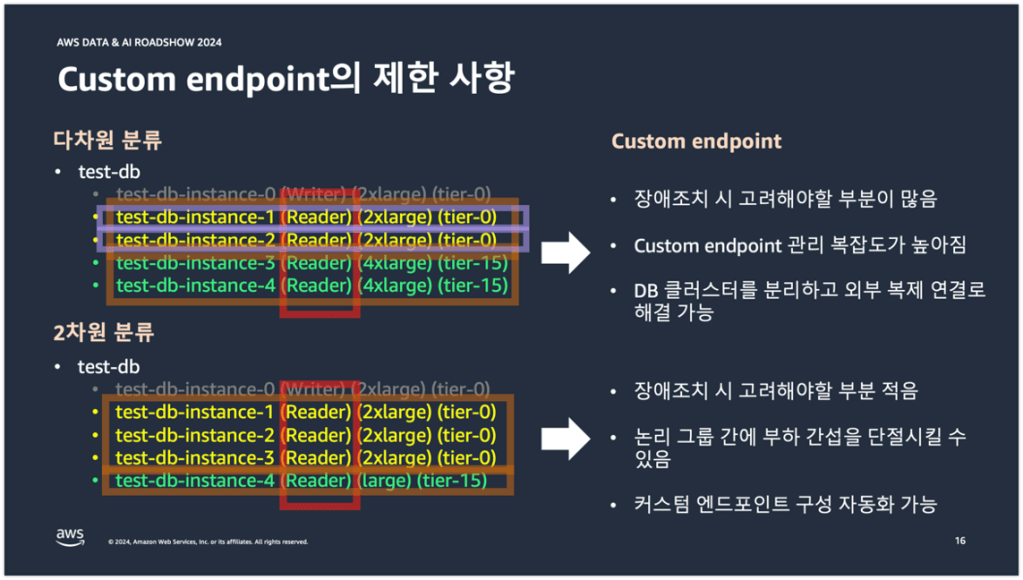
그럼 이제 3차원 분류 이상이 왜 엔드포인트 관리가 어려워지는 것인지를 살펴보겠다. 일단 장애조치를 할 때 고려해야될 부분이 많다. 예를 들어 test-db-instance-1과 test-db-instance-2가 장애조치 대상 DB 인스턴스라고 가정을 해보자. 각각의 DB 인스턴스는 위에서 살펴보았듯이 2개 이상의 커스텀 엔드포인트에 구성이 되어 있는 상태이다. 이 상황에서 Writer Role을 가진 test-db-instance-0이 Reader DB로 강등되면, test-db-instance-0도 2개의 커스텀 엔드포인트에 구성이 되어야 한다. 바로 이게 커스텀 엔드포인트의 관리 복잡도를 높이고, 장애조치 시 고려해야될 부분을 많게 만드는 점이다. 이렇게 3차원 분류 이상을 사용할 바에야 별도의 DB 클러스터로 분리하고 외부 복제 연결을 하거나 다른 방법을 사용하는 것이 서비스 운영 관리 측면에서 좀 더 효율적일 수 있다라는 것이다.
이번에는 2차원 분류도 살펴보도록 하겠다. 2차원 분류는 우선 장애조치를 할 때 고려해야될 부분이 적다. 왜냐하면 3차 분류에 대해서 장애조치를 신경쓰지 않아도 되니까 말이다. 그리고 서비스 읽기 전용 엔드포인트와 배치 전용 엔드포인트가 교차 지점 없이 논리적으로 완벽하게 분리되어 있기 때문에 서로 간에 부하 간섭을 단절 시킬 수 있다. 그리고 2차 분류라는 비교적 단순한 분류 때문에 커스텀 엔드포인트 구성을 자동화 해볼 수 있다는 특징도 가지고 있다.
이 제한 사항에 대해서 이야기를 하는 이유는 당근에서 2차원 분류를 사용하고 있기도 하고 혹시나 3차원 분류 이상을 생각하시는 분들이 있을 것 같아 노파심에 미리 공유를 드려보는 것이다.
Custom endpoint를 위한 Auto Scaling 적용 및 제한
사실 제목은 Custom endpoint를 위한 Auto Scaling 적용 및 제한이지만, 실제로는 서비스 읽기 전용 엔드포인트를 위한 Auto Scaling 적용 및 제한이라고 인지하고 내용을 읽으면 좋을 듯 하다. 목차 전체가 커스텀 엔드포인트에 초점이 맞추어져 있어서 Custom endpoint를 위한이라는 수식어구를 사용하긴 했지만 말이다.
Aurora의 Auto Scaling은 간단하게만 설명하면, Aurora 복제본의 수를 동적으로 조정하는 기능이다. 엔지니어가 부재 중일 때 서비스 트래픽이 급작스럽게 증가하면 자동으로 DB 인스턴스를 추가시켜주고, 서비스 트래픽이 감소하면 자동으로 DB 인스턴스를 삭제시켜준다. 그리고 이런 복제본의 수를 동적으로 조정하는 기준에는 Aurora 복제본의 평균 CPU 사용율과 DB 커넥션 수가 사용된다.

아래 중간의 test-db 클러스터는 당근의 DB 클러스터 구성과 동일한 3대 이상의 DB 인스턴스인 경우이다. 이 경우에 기본 설정된 Auto Scaling을 적용하게 되면 아래 화살표 오른쪽과 같이 Auto Scaling 동작 조건에 따라서 Auto Scaling DB 인스턴스가 1대가 추가된다.
그런데 기본 설정된 Auto Scaling은 DB 인스턴스의 사용 목적을 고려하지 않는다. 단순히 Reader 엔드포인트의 지표만으로 동작하기 때문에 당근에서와 같이 Read와 Batch 커스텀 엔드포인트를 나누어 사용하는 경우에는 사실상 기본 설정된 Auto Scaling은 적합한 사용 형태가 아니다.

순수하게 서비스에만 사용되는 CPU 사용률을 기준으로 Auto Scaling이 동작하게끔 만들어줄 필요가 있다.

하여 다음 내용으로는 그렇게 만들 수 있는 2가지 방법에 대해서 공유를 해보고자 한다.
먼저 2가지 방법 중 첫 번째 방법은 CloudWatch 산식 지표를 생성하는 방법이다.
기본 설정된 Auto Scaling을 추가하게 되면 CloudWatch 알람에 2가지의 알람이 생성된다. 하나는 High 알람이고, Low 알람이다. High 알람은 Auto Scaling이 Scale-out 되는 알람이고, Low 알람은 Auto Scaling이 Scale-in 되는 알람이다.
각 알람에 편집을 클릭하고 들어간다.
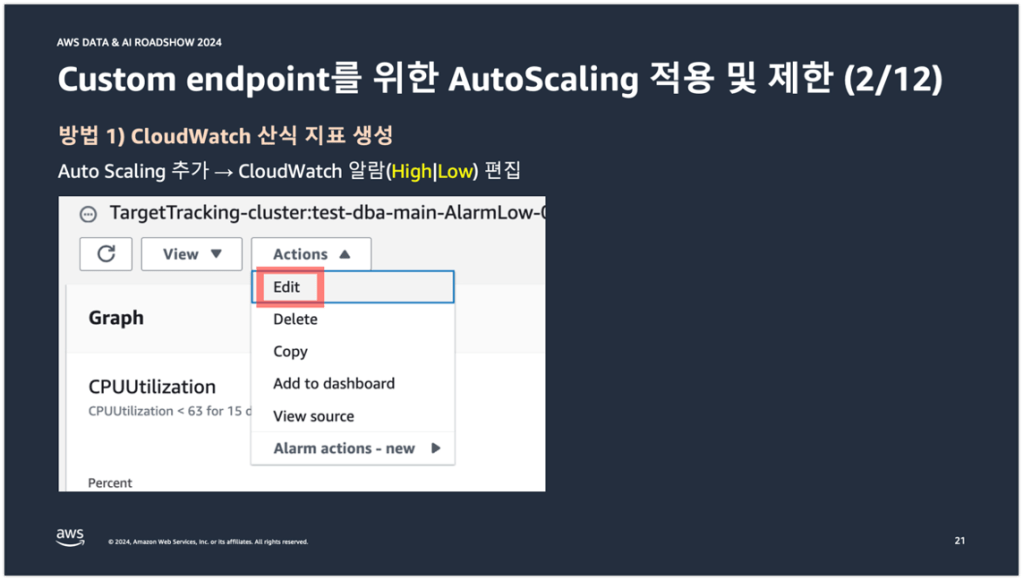
그러면 기본 설정된 Auto Scaling 동작 조건에 사용되는 CPUUtilization 지표를 확인할 수 있다. 이 메트릭에 편집을 클릭하고 들어간다.

그러면 CPUUtilization 지표가 그래프상에 그려져 있는 것을 확인할 수 있다.

화면 중간쯤에 보면 Add math라는 드롭박스가 있다. 그 드롭박스를 누르고 All functions에서 ABS 함수를 선택하고 산식 지표를 하나 추가해준다. 뒤에서 산식은 변경될 것이기 때문에 ABS 함수말고 다른 함수를 선택해도 상관은 없다.

추가된 산식 지표의 label을 편집하여 AutoScalingReaderCPUUtilization이라는 문자열로 변경을 해준다.
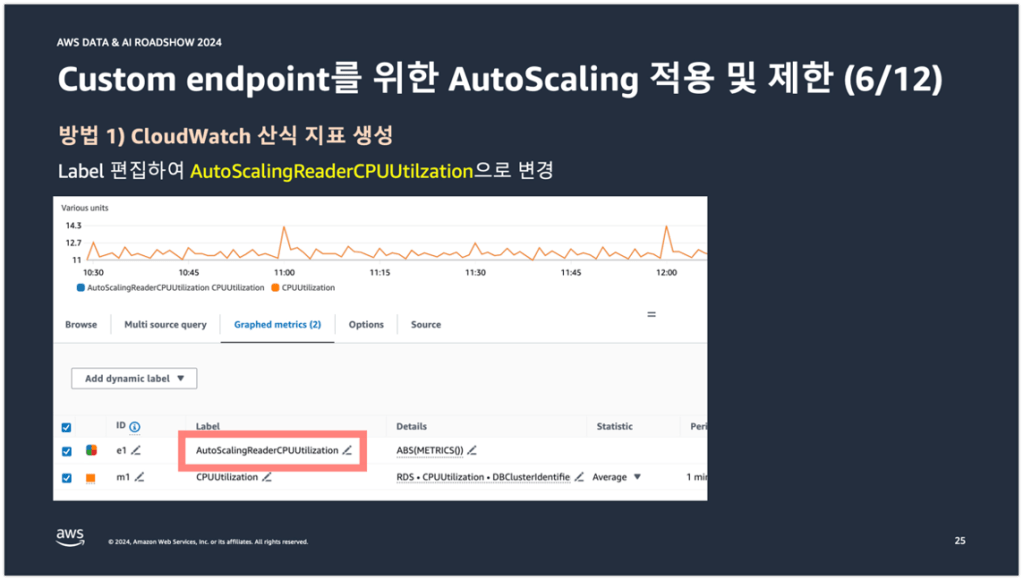
그리고 ABS 함수로 설정되어 있던 산식을 (m2-m1)/(m4-m3) 산식으로 설정해준다.
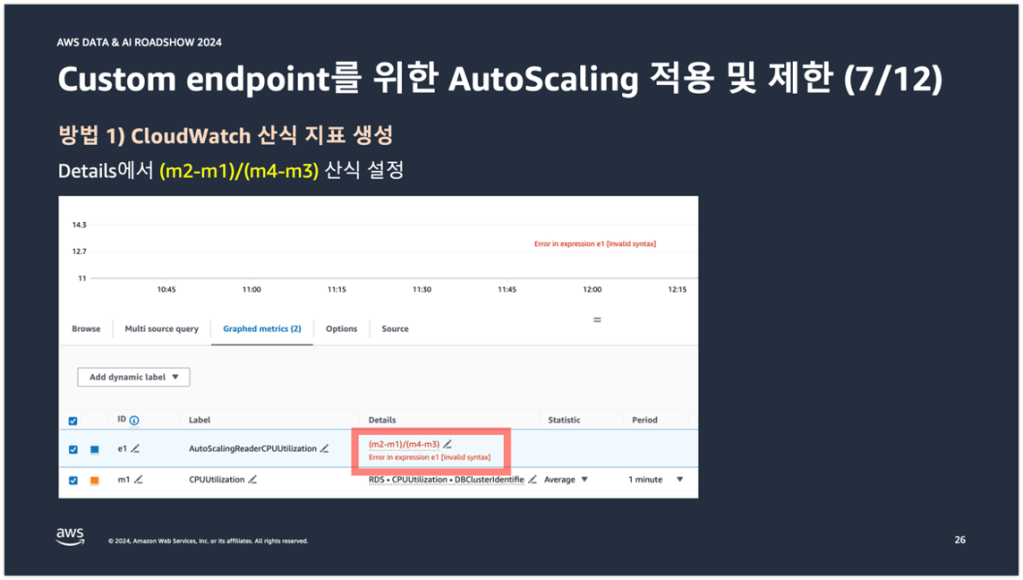
그 다음에는 m1, m2, m3, m4에 해당하는 CloudWatch 지표를 추가해서 AutoScalingReaderCPUUtilization 산식 지표를 계산하도록 만들어준다. 이 때 m1, m2, m3, m4는 아래 왼쪽 그림의 ID열에 해당되는데, 각 ID에 해당하는 값이 산식에 대입되어 AutoScalingReaderCPUUtilization 산식 지표가 계산되는 것이다. 여기서 산식의 의미는 Reader 엔드포인트에서 Batch DB 인스턴스는 제외하고 평균 CPU 사용률을 구하겠다라는 의미이다. 이렇게 Math expression을 사용하면 Batch DB 인스턴스를 Auto Scaling 동작 조건에서 제외시킬 수 있다.

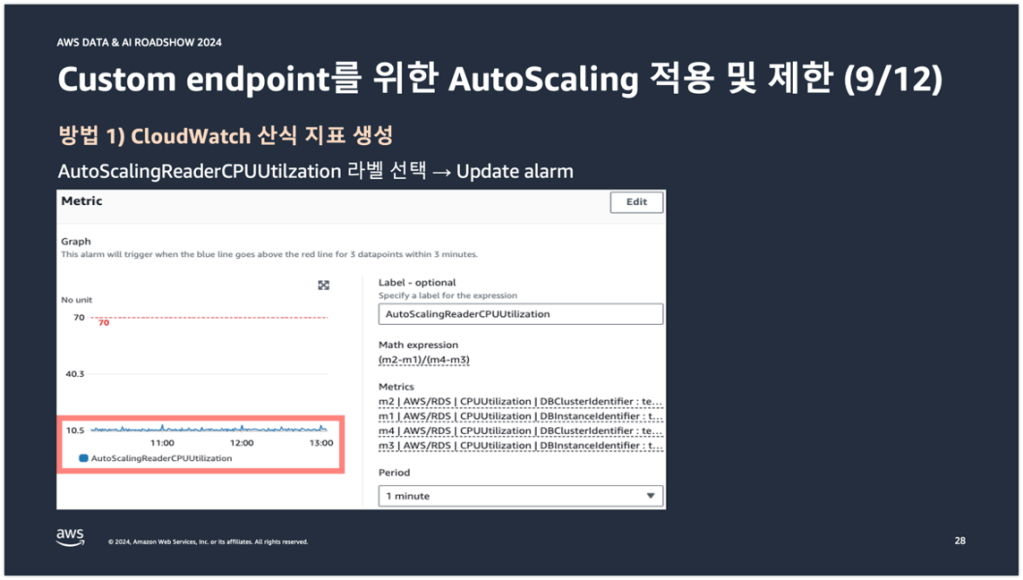
아까 전에는 Auto Scaling 동작 조건에 CPUUtilization이 사용되었는데, 현재는 AutoScalingReaderCPUUtilization 산식 지표가 Auto Scaling 동작 조건에 사용되는 것을 확인할 수 있다. 여기까지가 첫 번째 방법이다.
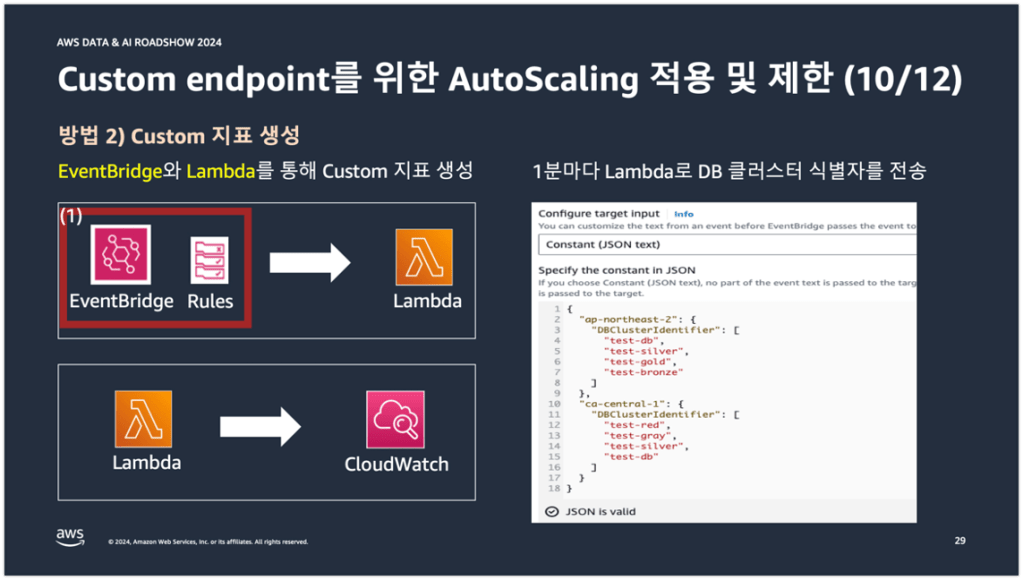
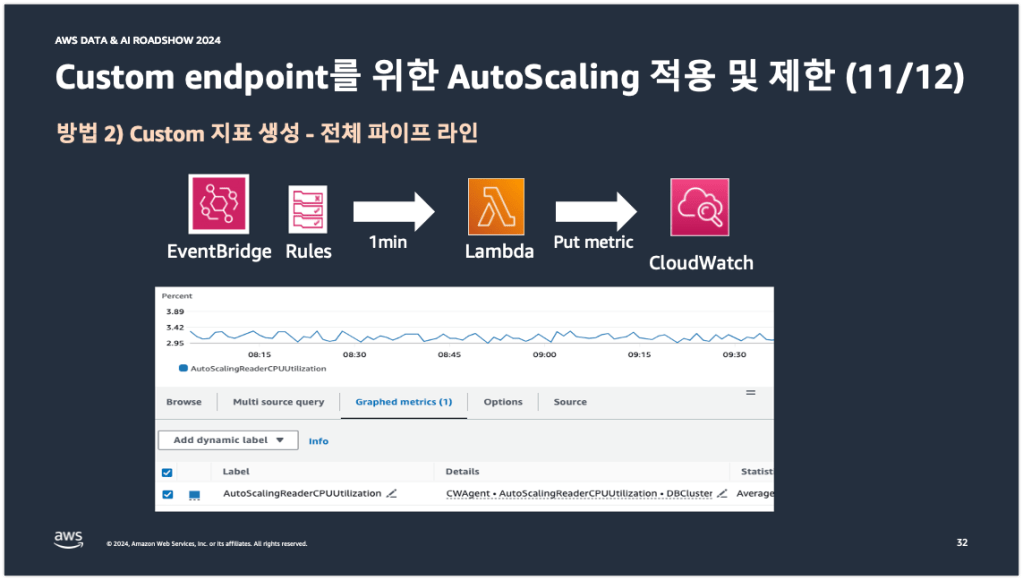
두 번째 방법은 CloudWatch 커스텀 지표를 생성하는 방법이다.
먼저 EventBridge Rules에서 아래 오른쪽 그림과 같이 Auto Scaling이 적용된 DB 클러스터 식별자를 리전별로 JSON 형태로 1분마다 Lambda 함수로 전송한다.
그러면 람다 함수에서는 DB 클러스터 식별자에 구성된 DB 인스턴스의 Role과 Name을 확인해서 Role이 Reader이고, Name에 batch 문자열이 들어간 DB 인스턴스는 평균 CPU 사용률 계산에서 제외시킨다.

그리고 제외시킨 값으로 AutoScalingReaderCPUUtilization 커스텀 지표를 생성하여 멀티 리전의 CloudWatch로 put metric을 수행한다.

그러면 첫 번째 방법과 같이 Auto Scaling 동작 조건에 AutoScalingReaderCPUUtilization 커스텀 지표가 사용되는 것을 확인할 수 있다.
그런데 두 번째 방법은 사실 한 가지 고려해야할 부분이 있다. 1개 람다 함수에서 멀티 리전의 DB 인스턴스 메트릭을 수집하기 때문에 DB 인스턴스의 수가 많을 수록 메트릭 수집 시간이 밀리는 문제가 발생할 수도 있는 것이다.
예를 들어, 1개 리전에서 1개 클러스터에 구성된 3개 인스턴스의 Custom 메트릭을 수집하는데 걸리는 시간이 1초라면, 리전이 4개이고, 리전당 클러스터가 25대이고, 클러스터당 DB 인스턴스가 3대이면, 여러 조건을 제외하더라도 최대 5분이 걸리게 된다. 이 말인 즉슨 람다 함수가 반복문을 돌면서 메트릭을 수집할텐데, 반복문의 마지막 수집 대상 DB 클러스터는 최근 5분 동안의 메트릭이 존재하지 않을 수도 있는 것이다. 그런데 이것이 Auto Scaling에서 어떤 의미로 받아들여지냐면, Auto Scaling 동작이 5분 늦게 반영되는 것으로 받아들여진다. 서비스 트래픽이 급작스럽게 증가해서 Auto Scaling이 동작해야 하는데 동작이 5분 늦게 반영되니까 DB 인스턴스도 5분 늦게 생성되는 것이다.
그래서 이 경우에는 리전별로 람다 함수를 생성해서 리전 수만큼의 람다 함수를 호출하던가, 아니면 1개 람다 함수내에서 리전별로 스레드를 생성하여 멀티 스레딩을 구현하던가 하는 방법으로 개선을 해야 한다.

Auto Scaling 알람 & 모니터링
다음은 Auto Scaling 알람 및 모니터링에 대한 내용이다. 먼저 Auto Scaling이 동작할 때 알람을 어떻게 받고 있는지부터 살펴보도록 하겠다.
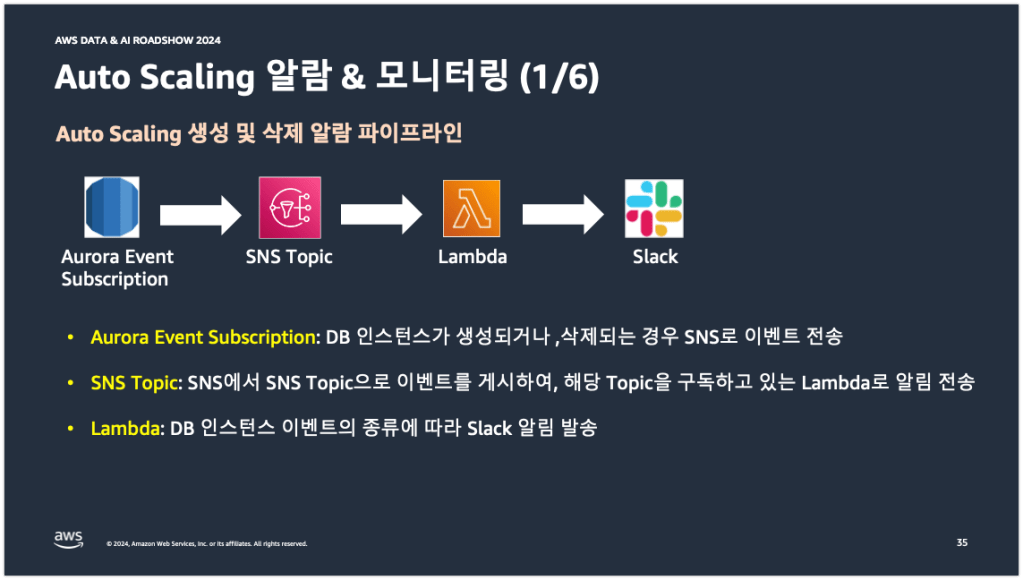
당근의 Auto Scaling 알람 파이프라인은 아래 중간의 그림과 같이 Aurora Event Subscription에서 SNS Topic에서 Lambda에서 Slack으로까지 구성되어 있다. 먼저 Aurora Event Subscription에서 DB 인스턴스가 추가되거나 삭제되면 관련 이벤트가 SNS로 전송되고, SNS는 SNS Topic으로 이벤트를 게시한다. 이어서 Topic을 구독하고 있던 Lambda 함수로 이벤트 알림이 전송되고 Lambda 함수에서는 추가되거나 삭제된 DB 인스턴스가 Auto Scaling에 의한 것인지, 사용자에 의한 것인지 판단해서 Slack으로 알람을 전송하게 된다.
아래 왼쪽 그림은 Aurora Event Subscription의 설정 화면이다. 빨간 박스에 보면 이벤트 카테고리에 creation, deletion 이벤트가 설정되어 있는 것을 확인할 수 있다. 이 2개 이벤트로 DB 인스턴스가 추가되거나 삭제되는 것을 감지한다.
아래 오른쪽 그림은 람다 함수의 코드를 일부 가져온 그림이다. Auto Scaling으로 DB 인스턴스가 생성되면 해당 DB 인스턴스는 application-autoscaling 이라는 문자열이 prefix로 무조건적으로 붙기 때문에 람다 함수 코드에서도 autoscaling 문자열을 가지고 추가되거나 삭제된 DB 인스턴스가 Auto Scaling에 의한 것인지, 사용자에 의한 것인지를 판단한다.

판단한 결과에 따라서 아래 오른쪽 그림과 같이 Scale-Out이면 스케일-아웃 알람을, Scale-In 알람이면 스케일-인 알람을 Slack으로 전송한다.

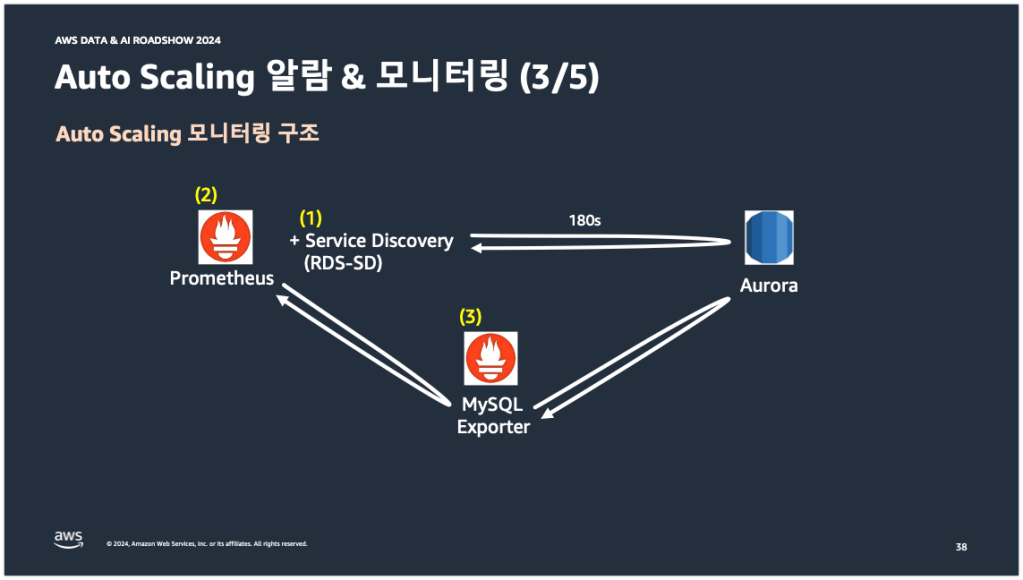
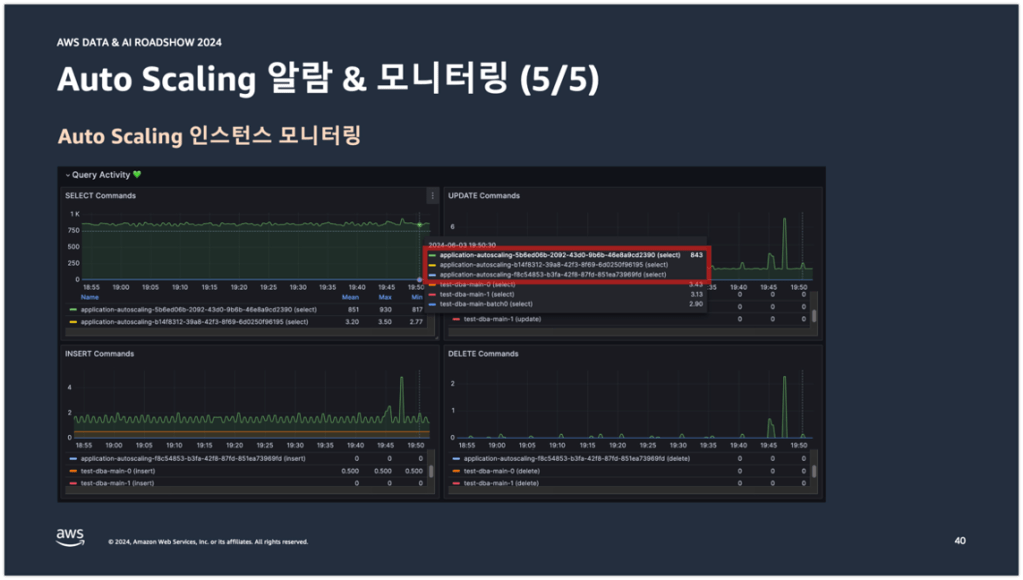
다음은 Auto Scaling 모니터링 구조이다. 아래 중간의 그림은 당근의 DB 서버 모니터링 구조를 간략하게 그림으로 나타낸 것이다. 그림에 적힌 번호 순서대로 설명을 진행해보겠다.
당근에서는 eks에 프로메테우스를 띄워서 DB 서버의 메트릭을 수집하고 있다. 그리고 수집된 메트릭을 바탕으로 그라파나에서 모니터링을 하고 있다. (1)번의 RDS-SD는 프로메테우스에 존재하는 여러 사이드카 패턴 중의 하나이다. Go로 작성된 RDS-SD 프로세스가 프로메테우스의 사이드카 패턴으로 별도의 컨테이너에 띄워져 있다. RDS-SD의 역할은 AWS SDK를 활용해서 AWS RDS의 메타 정보를 180초마다 조회해오는 것이다. 메타 정보안에는 DB 인스턴스의 DNS 정보, Role, Region, VPC 정보 등이 포함되어 있다. RDS-SD는 이 정보들을 바탕으로 JSON 파일을 생성한다. 그리고 (2)번에 해당하는 프로메테우스에서 JSON 파일을 읽어들인다. JSON 파일 안에는 메트릭을 수집하기 위한 DB 인스턴스의 타겟 정보가 포함되어 있다. 이 타겟 정보를 (3)번에 해당하는 MySQL Exporter에 Pull 방식으로 전달한다. 그러면 MySQL Exporter는 타겟 정보를 받아서 해당 DB 인스턴스의 메트릭을 수집하여 다시 프로메테우스로 메트릭을 전달한다(실제 처리 과정은 조금 다르지만 이해를 위해 이렇게 받아들여도 괜찮을 것이다). 그래서 대략 이런 흐름으로 DB 모니터링이 구성되어 있다.
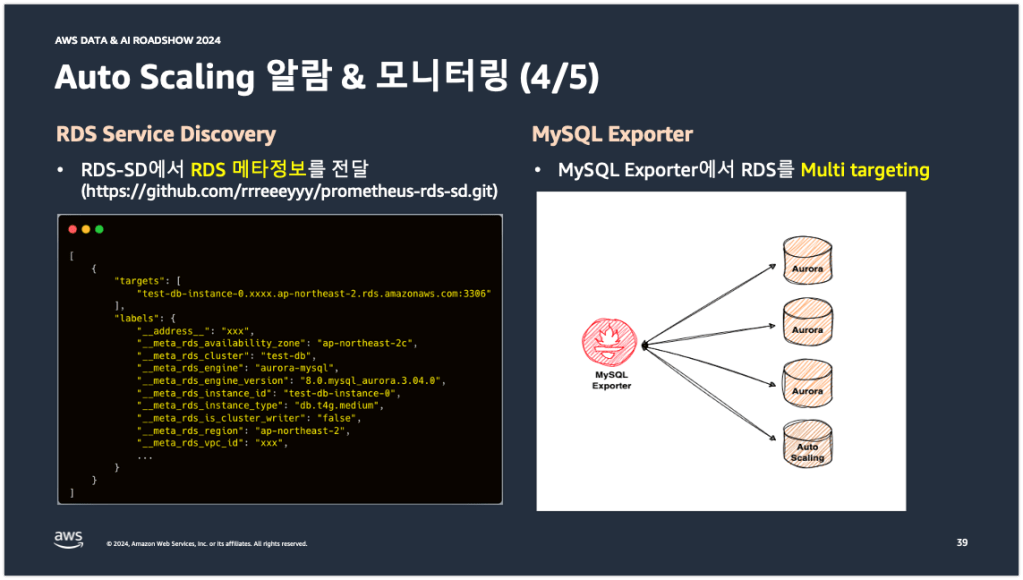
아래 왼쪽 그림은 RDS-SD 프로세스에서 조회하는 RDS 메타 정보이다. 메타 정보 안에는 targets라는 필드가 보이는데, 이 필드에 타겟 정보(DB 인스턴스의 DNS)가 포함되어 있다. 이 정보를 프로메테우스가 읽어들여서 MySQL Exporter로 전달하는 것이다.
아래 오른쪽 그림은 MySQL Exporter의 타겟팅 방식이다. 당근에 구성되어 있는 MySQL Exporter는 Static single targeting 방식이 아니라, Dynamic multi targeting 방식을 사용한다. MySQL Exporter 파드 하나가 여러대의 DB 인스턴스를 동적으로 타겟팅하고 있다. 이 말인 즉슨 Auto Scaling으로 불시에 DB 인스턴스가 추가되어도 MySQL Exporter가 해당 DB 인스턴스를 동적으로 인식하고 메트릭을 수집한다는 것이다.
그래서 아래 그림을 보면 application-autoscaling이라는 문자열 프리픽스가 붙은 DB 인스턴스가 다른 서비스 DB 인스턴스와 함께 모니터링 되고 있는 것을 확인할 수 있다.
이것으로 로드쇼에서 발표한 내용 정리를 끝마친다.

댓글 남기기