
아래 테스트 결과를 보면 InnoDB의 전문 검색(full-text search)은 격리 수준(=REPEATABLE-READ)이 적용되지 않는 것처럼 보인다. 오히려 커밋된 데이터를 읽는 READ-COMMITTED 격리 수준이 적용된 것처럼 보인다 ▼
CASE 1
| 세션 1 | 세션 2 |
|---|---|
| BEGIN; SELECT * FROM t1 WHERE MATCH(title) AGAINST (‘postgresql’ IN NATURAL LANGUAGE MODE); ===== 1. row ===== id: 3 title: Aurora PostgreSQL Database content: NULL | |
| UPDATE t1 SET title=’Oracle Database’ WHERE id = 3; | |
| SELECT * FROM t1 WHERE MATCH(title) AGAINST (‘postgresql’ IN NATURAL LANGUAGE MODE); Empty set (0.01 sec) | |
| SELECT * FROM t1 WHERE title LIKE ‘%postgresql%’; ===== 1. row ===== id: 3 title: Aurora PostgreSQL Database content: NULL |
InnoDB의 전문 검색 인덱스(full-text index) 관련 문서를 보면 아래와 같은 내용이 있다.
| InnoDB full-text indexes have special transaction handling characteristics due its caching and batch processing behavior. Specifically, updates and insertions on a full-text index are processed at transaction commit time, which means that a full-text search can only see committed data. (InnoDB의 전문 검색 인덱스는 캐싱 및 배치 처리 동작 때문에 특별한 트랜잭션 핸들링 특성을 가지고 있다. 특히, 전문 검색 인덱스의 UPDATE와 INSERT는 트랜잭션 커밋 시점에 처리되기 때문에 full-text 검색은 커밋된 데이터만 볼 수 있다.) |
문서에서 “full-text 검색은 커밋된 데이터만 볼 수 있다.” 라는 내용이 틀리지 않다면 위의 테스트 결과는 이상할 것이 하나도 없다. 세션 2에서 “Aurora PostgreSQL Database” 문자열을 “Oracle Database”로 변경하고 트랜잭션을 커밋했기 때문이다.
이번에는 아래 테스트 결과를 보겠다. CASE 1에서는 세션 2에서 업데이트를 수행한 이후, 세션 1에서 “postgresql” 단어에 대한 전문 검색을 수행했고, CASE 2에서는 세션 2에서 업데이트를 수행한 이후, 세션 1에서 “oracle” 단어에 대한 전문 검색을 수행했다 ▼
CASE 2
| 세션 1 | 세션 2 |
|---|---|
| BEGIN; SELECT * FROM t1 WHERE MATCH(title) AGAINST (‘postgresql’ IN NATURAL LANGUAGE MODE); ===== 1. row ===== id: 3 title: Aurora PostgreSQL Database content: NULL | |
| UPDATE t1 SET title=’Oracle Database’ WHERE id = 3; | |
| SELECT * FROM t1 WHERE MATCH(title) AGAINST (‘oracle’ IN NATURAL LANGUAGE MODE); Empty set (0.01 sec) |
전문 검색은 커밋된 데이터만 볼 수 있다고 했는데, “oracle” 단어에 대한 전문 검색 결과는 0건이다. 변경되기 전의 데이터(=Aurora PostgreSQL Database)도, 변경된 후의 데이터(=Oracle Database)도 조회되지 않는 것이다. 왜 이런 결과가 나온 것일까?
본 글의 주제와 결부지어서 보면,
CASE 1은 전문 검색 인덱스의 트랜잭션 핸들링과 관련이 있고, CASE 2는 InnoDB의 MVCC의 동작 방식과 관련이 있다.
CASE 1 – 전문 검색 인덱스의 트랜잭션 핸들링
전문 검색 인덱스는 기본적으로 반전 인덱스(inverted index)로 구성된 6개의 보조 인덱스(auxiliary index) 테이블과, 전문 검색 인덱스의 내부 상태나 삭제를 핸들링하는 5개의 공통 인덱스(common index) 테이블을 가진다.
+----------+------------------------------------------------------+-------+
| table_id | name | space |
+----------+------------------------------------------------------+-------+
| 3282 | silver/t1 | 2114 |
| 3283 | silver/fts_0000000000000cd2_being_deleted | 2115 |
| 3284 | silver/fts_0000000000000cd2_being_deleted_cache | 2116 |
| 3285 | silver/fts_0000000000000cd2_config | 2117 |
| 3286 | silver/fts_0000000000000cd2_deleted | 2118 |
| 3287 | silver/fts_0000000000000cd2_deleted_cache | 2119 |
| 3288 | silver/fts_0000000000000cd2_0000000000000ff1_index_1 | 2120 |
| 3289 | silver/fts_0000000000000cd2_0000000000000ff1_index_2 | 2121 |
| 3290 | silver/fts_0000000000000cd2_0000000000000ff1_index_3 | 2122 |
| 3291 | silver/fts_0000000000000cd2_0000000000000ff1_index_4 | 2123 |
| 3292 | silver/fts_0000000000000cd2_0000000000000ff1_index_5 | 2124 |
| 3293 | silver/fts_0000000000000cd2_0000000000000ff1_index_6 | 2125 |
+----------+------------------------------------------------------+-------+
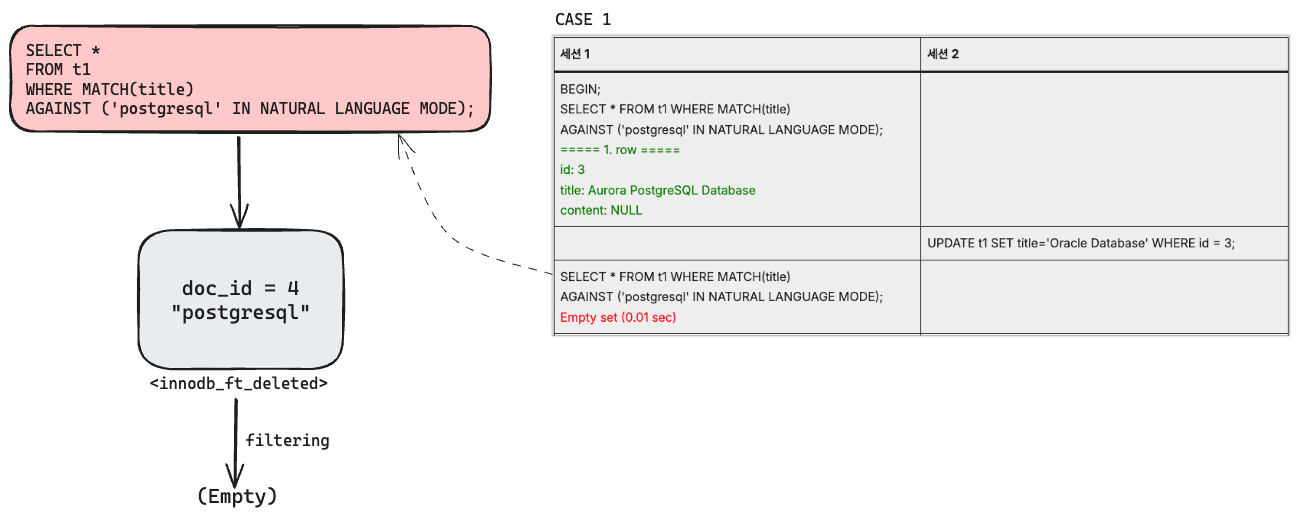
특정 문자열이 토큰화되고 여러 개별 단어로 분류되면 각 단어의 첫 번째 문자의 정렬 가중치에 따라 6개의 보조 인덱스 테이블로 데이터(=word)가 삽입된다. 하지만 하나의 문자열이라도 여러 작은 삽입(numerous small insertions) 경합(contention)이 발생할 수 있기 때문에 DML에 의한 신규 데이터는 innodb_ft_index_cache라는 메모리 엔진 임시테이블에 먼저 캐싱된다.
이와 비슷하게 데이터가 삭제된 경우에는 innodb_ft_deleted라는 임시테이블에 삭제된 데이터(=word)의 DOC_ID가 생성되며, 전문 검색을 수행할 때 삭제된 DOC_ID를 필터링 조건으로 사용한다. 이는 전문 검색 인덱스를 재구성할 때 드는 비용을 최소화하기 위함이며, 6개의 보조 인덱스 테이블에 반영하기 위해서는 OPTIMIZE TABLE 명령을 수행해야 한다.
CASE 1의 세션 2에서 t1 테이블의 title 컬럼 값을 업데이트하면, 신규 단어(database, oracle)가 생성되기 때문에 innodb_ft_index_cache 테이블에는 “database” 와 “oracle” 이라는 단어가 캐싱되며,
mysql> SELECT * FROM information_schema.innodb_ft_index_cache;
+----------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+----------+--------------+-------------+-----------+--------+----------+
| database | 7 | 7 | 1 | 7 | 7 |
| oracle | 7 | 7 | 1 | 7 | 0 |
+----------+--------------+-------------+-----------+--------+----------+
기존의 “postgresql” 이라는 단어를 “oracle” 로 대체했기 때문에 innodb_ft_deleted 테이블에는 삭제된 “postgresql” 단어의 DOC_ID(=4)가 저장된다.
mysql> SELECT * FROM information_schema.innodb_ft_index_table;
+------------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+------------+--------------+-------------+-----------+--------+----------+
| aurora | 2 | 4 | 2 | 2 | 0 |
| aurora | 2 | 4 | 2 | 4 | 0 |
| community | 3 | 3 | 1 | 3 | 6 |
| database | 2 | 5 | 4 | 2 | 13 |
| database | 2 | 5 | 4 | 3 | 16 |
| database | 2 | 5 | 4 | 4 | 18 |
| database | 2 | 5 | 4 | 5 | 8 |
| mongodb | 5 | 5 | 1 | 5 | 0 |
| mysql | 2 | 3 | 2 | 2 | 7 |
| mysql | 2 | 3 | 2 | 3 | 0 |
| postgresql | 4 | 4 | 1 | 4 | 7 |
+------------+--------------+-------------+-----------+--------+----------+
mysql> SELECT * FROM information_schema.innodb_ft_deleted;
+--------+
| DOC_ID |
+--------+
| 4 |
+--------+
여기서 중요한 것은, innodb_ft_index_cache 테이블과 innodb_ft_deleted 테이블의 커밋된 데이터는 트랜잭션이 열려있는 세션 1에서 언제든 참조가 가능하다는 것이다.
즉, 세션 2 업데이트 이후에 세션 1에서 “postgresql” 단어의 전문 검색 결과가 0건인 것은 innodb_ft_deleted 테이블에 의해 “postgresql” 단어가 속한 DOC_ID(=4)가 검색 결과에서 필터링 되었기 때문이다.
CASE 2 – InnoDB의 MVCC 동작 방식
CASE 2의 문제는 세션 2에서 커밋한 데이터(=oracle)가 innodb_ft_index_cache 테이블에 캐싱되었음에도 이후 세션 1의 전문 검색 결과가 0건인 것이었다. “full-text 검색은 커밋된 데이터만 볼 수 있다.” 라는 문서의 내용을 토대로, 실제로 전문 검색이 MVCC와 어떠한 관련이 있는지 살펴보도록 하겠다.
CASE 2의 원인을 파악하기 위해 가장 먼저 확인해봐야할 것은, 세션 1에서 innodb_ft_index_cache 테이블에 캐싱된 DOC_ID를 참조하였는가이다. DOC_ID를 참조하였다면 참조 이후 처리 과정에 원인이 있는 것이고, 참조하지 않았다면 innodb_ft_index_cache 테이블을 참조하지 않는 것에 원인이 있는 것이다.
그런데 사실 이 과정은 의외로 쉽게 확인할 수 있다. ha_innodb.cc 파일의 ft_read() 함수를 보면 search_doc_id에 ranking->doc_id가 저장되는 것을 확인할 수 있는데(5번째 줄) 이 search_doc_id에, 캐싱된 “oracle” 데이터의 DOC_ID가 저장되면 세션 1은 innodb_ft_index_cache 테이블을 참조하는 것이다.
(search_doc_id는 uint64_t에 대한 타입 별칭 doc_id_t이다.)
int ha_innobase::ft_read(uchar *buf) /*!< in/out: buf contain result row */
{
...
...
search_doc_id = ranking->doc_id;
/* We pass a pointer of search_doc_id because it will be
converted to storage byte order used in the search
tuple. */
innobase_fts_create_doc_id_key(tuple, index, &search_doc_id);
auto ret = innobase_srv_conc_enter_innodb(m_prebuilt);
if (ret == DB_SUCCESS) {
ret = row_search_for_mysql((byte *)buf, PAGE_CUR_GE, m_prebuilt,
ROW_SEL_EXACT, 0);
innobase_srv_conc_exit_innodb(m_prebuilt);
}
세션 2에서 업데이트한 이후 innodb_ft_index_cache 테이블에 캐싱된 “oracle” 데이터(=word)의 DOC_ID는 7이다.
mysql> SELECT * FROM information_schema.innodb_ft_index_cache WHERE word = 'oracle';
+----------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+----------+--------------+-------------+-----------+--------+----------+
| database | 7 | 7 | 1 | 7 | 7 |
+----------+--------------+-------------+-----------+--------+----------+
그리고 쿼리 수행 시점에 ranking->doc_id를 출력해보면 이 값 또한 7이다(12번째 줄).
Process 4586 stopped
* thread #42, name = 'connection', stop reason = step over
frame #0: 0x000000010249d604 mysqld`ha_innobase::ft_read(this=0x00000001310d6830, buf="\U00000002\U00000003") at ha_innodb.cc:11492:21
11489
11490 fts_ranking_t *ranking = rbt_value(fts_ranking_t, result->current);
11491
-> 11492 search_doc_id = ranking->doc_id;
11493
11494 /* We pass a pointer of search_doc_id because it will be
11495 converted to storage byte order used in the search
(lldb) p ranking->doc_id
(doc_id_t) 7
이 결과를 통해 세션 1은 innodb_ft_index_cache 테이블에 캐싱된 DOC_ID를 참조한다는 것을 확인할 수 있다. 세션 1의 전문 검색 결과가 0건인 이유는 참조 이후 처리 과정에 있는 것이다.
코드를 계속 이어서 살펴보겠다. 이제는 이후 처리 과정에 원인을 두고 분석을 이어나가야 한다.
DOC_ID를 찾은 이후에 이어서 전문 검색 인덱스 정보가 담긴 구조체(m_prebuilt)와 함께 row_search_for_mysql() 함수를 호출한다. 이 때 현재 테이블 정보가 intrinsic한지 검사하는 과정이 있는데, InnoDB 스토리지 엔진 내부적으로 생성된 테이블인지를 검사해서 아닌 경우에만 row_search_mvcc() 함수를 호출한다. CASE 2의 경우 아래 코드에서 row_search_mvcc() 함수를 호출한다.
static inline dberr_t row_search_for_mysql(byte *buf, page_cur_mode_t mode,
row_prebuilt_t *prebuilt,
ulint match_mode, ulint direction) {
if (!prebuilt->table->is_intrinsic()) {
return (row_search_mvcc(buf, mode, prebuilt, match_mode, direction));
} else {
return (row_search_no_mvcc(buf, mode, prebuilt, match_mode, direction));
}
}
row_search_mvcc() 함수 내부에는 ReadView 구조체를 할당하는 함수가 존재하는데, 이 함수를 호출하면 현재 트랜잭션 ReadView 객체의 포인터가 반환된다.
dberr_t row_search_mvcc(byte *buf, page_cur_mode_t mode,
row_prebuilt_t *prebuilt, ulint match_mode,
const ulint direction) {
...
...
if (!srv_read_only_mode) {
trx_assign_read_view(trx);
}
...
...
InnoDB에서 MVCC 메커니즘이 동작하는 방식에 있어서 ReadView가 생성되는 시점은 트랜잭션이 시작되는 시점이 아니라 SELECT 문장이 수행되는 시점이다. 이 때 공유 메모리에 기생성되어 있는 TRX_SYS 구조체의 정보를 바탕으로 ReadView 구조체가 새롭게 할당되는데, 이렇게 생성된 ReadView는 자신이 볼 수 있는 데이터의 가시 범위가 구조체가 할당되는 과정에서 결정된다.
trx_assign_read_view() 함수 정의에서 14번째 줄 코드를 보면 trx->read_view가 반환되는 것을 확인할 수 있다.
ReadView *trx_assign_read_view(trx_t *trx) /*!< in/out: active transaction */
{
ut_ad(trx_can_be_handled_by_current_thread_or_is_hp_victim(trx));
ut_ad(trx->state.load(std::memory_order_relaxed) == TRX_STATE_ACTIVE);
if (srv_read_only_mode) {
ut_ad(trx->read_view == nullptr);
return (nullptr);
} else if (!MVCC::is_view_active(trx->read_view)) {
trx_sys->mvcc->view_open(trx->read_view, trx);
}
return (trx->read_view);
}
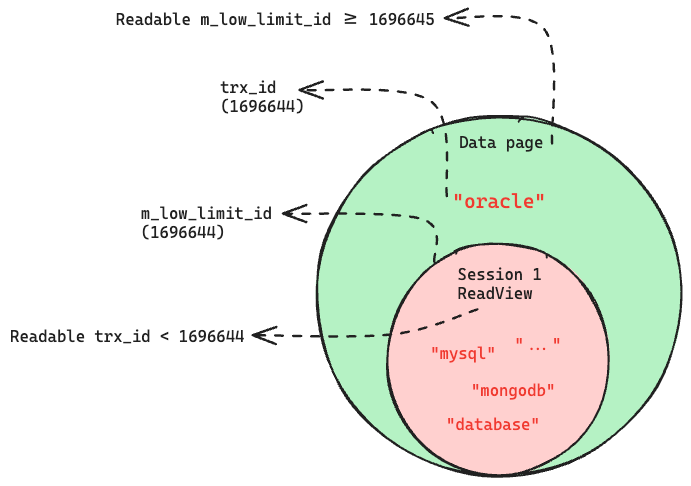
“oracle” 데이터(=word)를 전문 검색하는 시점에 ReadView를 출력해보면, 아래와 같은 정보를 확인할 수 있는데, ReadView 구조체 멤버 변수 중 m_low_limit_id 변수는 ReadView의 가시 범위를 결정하는 중요한 역할을 한다. 이 ReadView가 데이터를 읽을 수 있는 가시 범위는 m_low_limit_id 값보다 작은 trx_id를 가진 데이터 페이지 또는 언두 페이지이다.
(ReadView) {
m_low_limit_id = 1696644
m_up_limit_id = 1696644
m_creator_trx_id = 0
m_ids = {
m_ptr = 0x0000000000000000
m_size = 0
m_reserved = 0
}
m_low_limit_no = 1696628
m_view_low_limit_no = 1696628
m_closed = false
pad1 = ""
m_view_list = {
prev = nullptr
next = nullptr
}
}
아래 그림과 같이 세션 1의 ReadView는 m_low_limit_id(=1696644) 값보다 크거나 같은 trx_id의 데이터는 읽을 수 없다. 즉 m_low_limit_id 값이 최소 1696645는 되어야 “oracle” 단어가 포함된 레코드를 읽을 수 있다는 의미이다.
다음과 같이 세션 1의 ReadView 가시 범위를 +1로 조정하고, 조회 결과를 다시 한 번 확인해보겠다.
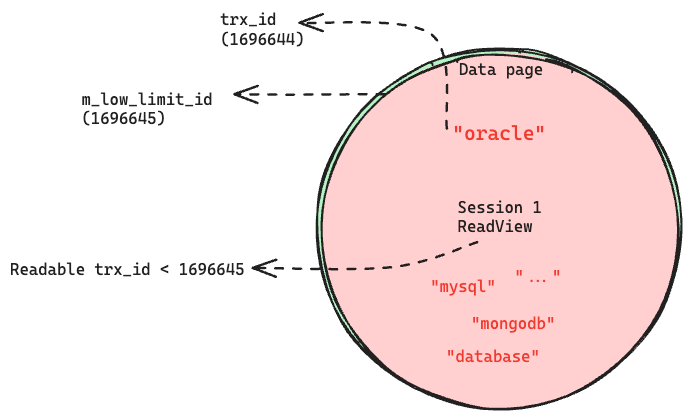
expr trx->read_view->m_low_limit_id = 1696645 // (1696644 + 1)
expr trx->read_view->m_up_limit_id = 1696645 // (1696644 + 1)
expr trx->read_view->m_low_limit_no = 1696629 // (1696628 + 1)
expr trx->read_view->m_view_low_limit_no = 1696729 // (1696728 + 1)
ReadView의 가시 범위를 +1만큼 증가시켰기 때문에 CASE 2의 세션 1 결과와는 다르게, “oracle” 단어가 포함된 레코드가 조회되는 것을 확인할 수 있다.
# m_low_limit_id를 증가시키면 레코드를 읽을 수 있다.
SELECT * FROM t1 WHERE MATCH(title) AGAINST ('oracle' IN NATURAL LANGUAGE MODE);
+----+-----------------+---------+
| id | title | content |
+----+-----------------+---------+
| 3 | Oracle Database | NULL |
+----+-----------------+---------+
임시적이지만 ReadView의 가시 범위가 아래 그림과 같이 변경된 것이다.
정리
- ① 세션 1은 SELECT문을 수행하면서 TRX_SYS 구조체로부터 trx_id가 1696644인 ReadView를 할당받는다.
- ② 세션 2는 UPDATE문을 수행하면서 TRX_SYS 구조체로부터 trx_id가 1696644인 트랜잭션 구조체를 할당받고,
- ③ TRX_SYS의 max trx_id는 +1 증가한다.
- ④ 세션 1에서 “oracle”에 대한 전문검색을 수행하면 데이터 페이지의 trx_id를 확인하고 ReadView가 가진 trx_id(m_low_limit_id)보다 작은지 확인한다.
- ⑤ 결국 ReadView의 trx_id보다 작은 언두 페이지를 찾지만 “oracle”에 해당하는 데이터는 찾을 수 없다.
- ⑥ m_low_limit_id 값을 임의로 +1 증가시키고 재조회하면, 데이터 페이지의 trx_id가 ReadView의 trx_id보다 작으므로 “oracle” 단어에 해당하는 레코드를 찾게 된다.

결국 full-text 검색은 커밋된 데이터만 볼 수 있다고 해도, 최종적으로는 InnoDB의 MVCC 메커니즘을 따르게 되어 있고, 최신 커밋된 DOC_ID를 읽을 수 있을지언정 ReadView의 가시 범위 제약으로 인해 검색 결과는 얻을 수 없다.
참고
아래는 함수 호출 스택이며, 본 내용을 이해하는데 참고하면 된다.
1) ref_row_iterators.cc
int FullTextSearchIterator::Read()
2) handler.cc
result = ft_read(buf);
3) ha_innodb.cc
ha_innobase::ft_read()
fts_ranking_t *ranking = rbt_value(fts_ranking_t, result->current);
# 전문 검색 인덱스 정보가 담긴 구조체와 함께 row_search_for_mysql() 함수를 호출한다.
row_search_for_mysql((byte *)buf, PAGE_CUR_GE, m_prebuilt, ROW_SEL_EXACT, 0);
4) row0sel.ic
# t1 테이블이 내부적으로 사용되는 테이블인지 임시 테이블인지를 판단하여 row_search_mvcc() 함수 호출
row_search_for_mysql()
row_search_mvcc(buf, mode, prebuilt, match_mode, direction)
5) row0sel.cc
# SELECT문의 잠금 유형(LOCK_TYPE)이 LOCK_NONE이면 ReadView 생성
trx_assign_read_view()
6) trx0trx.cc
# ReadView 반환
p *trx->read_view
(ReadView) {
m_low_limit_id = 1696644
m_up_limit_id = 1696644
m_creator_trx_id = 0
m_ids = {
m_ptr = 0x0000000000000000
m_size = 0
m_reserved = 0
}
m_low_limit_no = 1696628
m_view_low_limit_no = 1696628
m_closed = false
pad1 = ""
m_view_list = {
prev = nullptr
next = nullptr
}
}
5) row0sel.cc
4) row0sel.ic
3) ha_innodb.cc
case DB_RECORD_NOT_FOUND:
...
error = HA_ERR_END_OF_FILE;
default:
break;
return (HA_ERR_END_OF_FILE);

댓글 남기기