
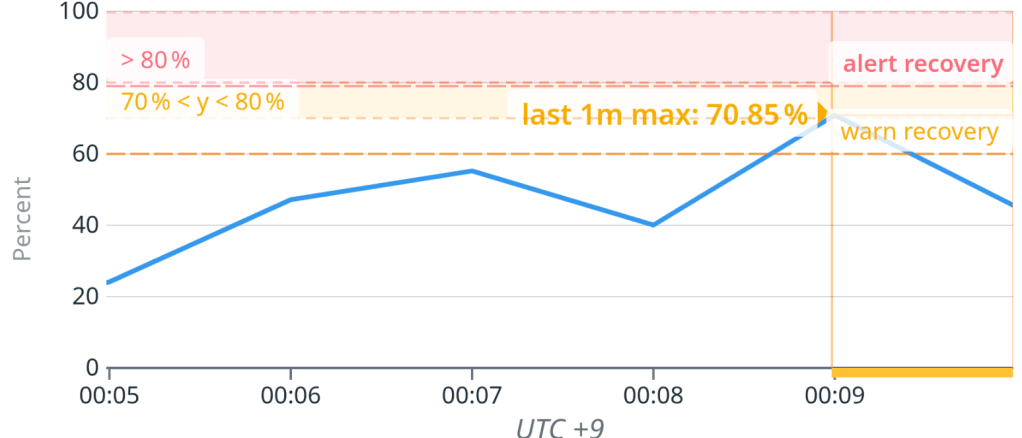
최근 CPU 사용율이 70%를 넘어간 DB 인스턴스가 있어서 원인을 살펴보다가 조치 내용을 공유하면 좋을 것 같아 글을 작성한다.
Performance Insights를 보면 정규화된 쿼리에 묶인, 실제로 수행된 쿼리들이 보인다. 좀 더 자세히 보면 sql handler 대기 시간이 유난히 긴 특정 쿼리가 보이는데, 해당 쿼리가 대부분의 DB 부하를 차지하고 있다는 것을 알 수 있다.

페이징 쿼리
이 쿼리는 다음과 같다.
(객체 명칭은 전부 임의로 변경했지만 구조는 동일하다)
SELECT *
FROM silver_cost AS sc
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > 0
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
육안으로 보기에 아무런 이상이 없는 단순한 페이징 쿼리이다. 이 페이징 쿼리를 페이징답게 수행하려면 (silver_cost_item_id, id) 구성의 세컨더리 인덱스가 반드시 존재해야 하는데, 인덱스도 문제없이 잘 생성되어 있다.
CREATE TABLE silver_cost (
id bigint NOT NULL AUTO_INCREMENT,
silver_cost_item_id bigint DEFAULT NULL,
...
PRIMARY KEY (id),
KEY ix_silvercostitemid_id (silver_cost_item_id, id),
...
) ENGINE=InnoDB AUTO_INCREMENT=12686471 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
이대로만 수행된다면 2회차, 3회차, N회차 쿼리도 효율적으로 수행될 것이다.
-- 1회차
SELECT *
FROM silver_cost AS sc
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > 0
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
-- 2회차
SELECT *
FROM silver_cost AS sc
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > {1회차의 id 최대값}
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
-- 3회차
SELECT *
FROM silver_cost AS sc
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > {2회차의 id 최대값}
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
-- N회차
SELECT *
FROM silver_cost AS sc
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > {(n-1)회차의 id 최대값}
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
하지만 실제로는 1회차 쿼리 수행에서 20초 이상이 소요된다. 왜 그럴까?
데이터 분포
쿼리 실행계획을 보면 어느정도 이해가 된다. 예상한 것과는 다르게 ix_silvercostitemid_id 인덱스를 사용하지 않고, PK 인덱스를 사용한다.
+-------+-------+--------------------------------+---------+---------+-------+----------+----------+-------------+
| table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+-------+-------+--------------------------------+---------+---------+-------+----------+----------+-------------+
| si | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| sc | range | PRIMARY,ix_silvercostitemid_id | PRIMARY | 8 | NULL | 14184789 | 10.00 | Using where |
+-------+-------+--------------------------------+---------+---------+-------+----------+----------+-------------+
-> Limit: 10 row(s) (cost=993196.49 rows=10)
-> Filter: ((sc.silver_cost_item_id = 500) and (sc.id > 0)) (cost=993196.49 rows=1418479)
-> Index range scan on sc using PRIMARY over (0 < id) (cost=993196.49 rows=14184789)
sc.id > 0 조건에 해당하는 모든 레코드를 스캔하다보니 1회차에서는 쿼리 수행 시간이 20초 이상 소요되는 것이다. 그런데 여기서 생각해볼 것은 PK 스캔을 수행하여도 LIMIT 조건을 만족하는 레코드 10건만 찾으면 그렇게 오래 소요될만한 쿼리는 아니라는 것이다. 그러면 무슨 이유 때문일까.
다음의 쿼리 결과를 보면 그 이유를 명확히 알 수 있다.
SELECT COUNT(*), silver_cost_item_id FROM silver_cost GROUP BY silver_cost_item_id ORDER BY id;
+----------+-------------------------+
| count(*) | silver_cost_item_id |
+----------+-------------------------+
| 3558 | 1 |
...
... row = 117개, total count = 3,000만건
...
| 351634 | 500 |
| 351637 | 600 |
| 133697 | 700 |
| 133697 | 800 |
+----------+-------------------------+
silver_cost_item_id = 500 조건에 해당하는 레코드가 id 순서 기준, 전부 끝에 몰려있다. 즉 조건을 만족하는 10건의 레코드를 조회하기 위해 3,000만건 이상의 레코드를 스캔해야 되는 것이다.
-- silver_cost_item_id = 500에 해당하는 레코드 구간의 id 최소/최대값
SELECT MAX(id), MIN(id), silver_cost_item_id FROM silver_cost WHERE silver_cost_item_id = 500
+----------+----------+-------------------------+
| max(id) | min(id) | silver_cost_item_id |
+----------+----------+-------------------------+
| 45759878 | 45408245 | 500 |
+----------+----------+-------------------------+
-- silver_cost 테이블의 id 최대값
SELECT MAX(id) FROM silver_cost;
+----------+
| MAX(id) |
+----------+
| 45759878 |
+----------+
이를 증명하기 위한 내림차순 조회는 당연히 코스트도 낮고 쿼리 수행도 빠르다.
SELECT *
FROM silver_cost AS sc FORCE INDEX(primary)
JOIN silver_item si on sc.silver_cost_item_id = si.id
and si.is_deleted = 0
WHERE sc.id > 0
AND sc.silver_cost_item_id = 500
ORDER BY sc.id DESC
LIMIT 10;
10 rows in set (0.36 sec)
-> Limit: 10 row(s) (cost=7543.10 rows=1)
-> Filter: (sc.silver_cost_item_id = 500) (cost=7543.10 rows=1)
-> Index scan on sc using PRIMARY (reverse) (cost=7543.10 rows=10)
페이징 쿼리 첫 단추
해당 쿼리의 실행 소요 시간이 길 수밖에 없는 이유는 확인했다. 그러면 N회차의 쿼리가 잘 수행되도록 페이징 쿼리의 첫 단추를 어떻게 매듭지으면 될까.
이 쿼리의 좀 더 근본적인 문제는 sc.id > 0 조건이다. 이 조건으로 인해 레코드 스캔 범위의 하한선이 생기면서 옵티마이저가 여러 최적화를 시도하게 된다. 여러 최적화를 시도하는 과정에서 비효율적인 판단을 하게 되는 것이다.
사실 옵티마이저는 considered execution plan 단계에서 ix_silvercostitemid_id 범위(silver_cost_item_id AND id>0)와 PK를 row-order intersect로 묶는 실행계획을 거의 최종적으로 선택한다(23, 27번째 줄).
{
"considered_execution_plans": [
{
"plan_prefix": [
"`silver_item` `si`"
],
"table": "`silver_cost` `sc`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "ix_silvercostitemid_id",
"chosen": false,
"cause": "range_uses_more_keyparts"
},
{
"rows_to_scan": 351815,
"filtering_effect": [
],
"final_filtering_effect": 1,
"access_type": "range",
"range_details": {
"used_index": "intersect(ix_silvercostitemid_id,PRIMARY)"
},
"resulting_rows": 351815,
"cost": 139663,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 351815,
"cost_for_plan": 139663,
"chosen": true
}
]
},
그런데 예상 행 수(351K) 대비 LIMIT이 너무 작아서(10), 재검사(recheck)가 필요하겠다는 판단을 하고 최적화 과정을 한 번 더 거친다. 그리고 이 때 사용 가능한 범위 인덱스를 다시 찾는데, 아래 20번째 줄에 나와있듯이 이 단계에서 판단 가능한 key part는 id 필드이기 때문에 이미 상수 조건(=500)을 사용한 ix_silvercostitemid_id 인덱스는 고려 대상에서 제외된다(24~26번째 줄). 반면에 PK는 id 필드를 사용할 수 있기 때문에 usable true로 최종 선택된다(41번째 줄).
"attaching_conditions_to_tables": {
"original_condition": "((`i1_0`.`silver_cost_item_id` = 500) and (`i1_0`.`id` > 0))",
"attached_conditions_computation": [
{
"table": "`silver_cost` `i1_0`",
"rechecking_index_usage": {
"recheck_reason": "low_limit",
"limit": 10,
"row_estimate": 351815,
"range_analysis": {
"table_scan": {
"rows": 28510896,
"cost": 9.97882e+06
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": true,
"key_parts": [
"id"
]
},
{
"index": "ix_silvercostitemid_id",
"usable": false,
"cause": "not_applicable"
},
...
...
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "PRIMARY",
"rows": 1.42554e+07,
"ranges": [
"0 < id"
]
},
"rows_for_plan": 1.42554e+07,
"cost_for_plan": 1.43324e+06,
"chosen": true
recheck 코드는 사용 가능한 키를 판별할 때 키 맵에 table->keys()를 박아버리기 때문에(27번째 줄) table-> const_keys에만 들어가있는 상수 조건인 sc.silver_cost_item_id = 500은 고려 조차도 안한다. 이로 인해 잘못된 선택을 하는데도 말이다. 개선이 필요한 부분이다.
if (recheck_reason != DONT_RECHECK) {
Opt_trace_object trace_one_table(trace);
trace_one_table.add_utf8_table(tab->table_ref);
Opt_trace_object trace_table(trace, "rechecking_index_usage");
if (recheck_reason == NOT_FIRST_TABLE)
trace_table.add_alnum("recheck_reason", "not_first_table");
else
trace_table.add_alnum("recheck_reason", "low_limit")
.add("limit", join->query_expression()->select_limit_cnt)
.add("row_estimate", tab->position()->rows_fetched *
tab->position()->filter_effect);
/* Join with outer join condition */
Item *orig_cond = tab->condition();
tab->and_with_condition(tab->join_cond());
/*
We can't call sel->cond->fix_fields,
as it will break tab->join_cond() if it's AND condition
(fix_fields currently removes extra AND/OR levels).
Yet attributes of the just built condition are not needed.
Thus we call sel->cond->quick_fix_field for safety.
*/
if (tab->condition() && !tab->condition()->fixed)
tab->condition()->quick_fix_field();
Key_map usable_keys = tab->keys();
enum_order interesting_order = ORDER_NOT_RELEVANT;
if (recheck_reason == LOW_LIMIT) {
int read_direction = 0;
튜닝 방안
그래서 결론적으로 이렇게까지 깊게 볼 내용은 아니었지만…깊게 본 것치고 조치 내용은 너무 간단하다. 페이징 쿼리를 최초 수행할 때만 sc.id > 0 조건을 제외해주면 된다. 들어가 있었던 것도 의아하지만, 그러면 정상적으로 쿼리가 빠르게 수행된다.
-- 수정 전
SELECT *
FROM silver_cost AS sc
JOIN silver_item si ON sc.silver_cost_item_id = si.id
AND si.is_deleted = 0
WHERE sc.id > 0
AND sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
-- 수정 후
SELECT *
FROM silver_cost AS sc
JOIN silver_item si ON sc.silver_cost_item_id = si.id
AND si.is_deleted = 0
WHERE sc.silver_cost_item_id = 500
ORDER BY sc.id
LIMIT 10;
-- 수정 전과 후의 Handler API 횟수 비교
+----------------------------+----------++----------------------------+-------+
| Variable_name | Value || Variable_name | Value |
+----------------------------+----------++----------------------------+-------+
| Handler_commit | 1 || Handler_commit | 1 |
| Handler_delete | 0 || Handler_delete | 0 |
| Handler_discover | 0 || Handler_discover | 0 |
| Handler_external_lock | 4 || Handler_external_lock | 4 |
| Handler_mrr_init | 0 || Handler_mrr_init | 0 |
| Handler_prepare | 0 || Handler_prepare | 0 |
| Handler_read_first | 0 || Handler_read_first | 0 |
| Handler_read_key | 2 || Handler_read_key | 2 |
| Handler_read_last | 0 || Handler_read_last | 0 |
| Handler_read_next | 28180109 || Handler_read_next | 9 |
| Handler_read_prev | 0 || Handler_read_prev | 0 |
| Handler_read_rnd | 0 || Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 || Handler_read_rnd_next | 0 |
| Handler_rollback | 0 || Handler_rollback | 0 |
| Handler_savepoint | 0 || Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 || Handler_savepoint_rollback | 0 |
| Handler_update | 0 || Handler_update | 0 |
| Handler_write | 0 || Handler_write | 0 |
+----------------------------+----------++----------------------------+-------+
튜닝 이후 CPU 사용율이 10% 이상 감소한 것을 확인할 수 있다.

댓글 남기기