
대 AI 시대에 DBA 성역을 고집하면서도 AI와 가까워지려 하는 것은 참으로 아이러니한 일이다. 데이터베이스 지식 전파에 헌신한 이들에게 AI와 나란히 서서 참배하는 상상은 왜 이 상상이 실현되려 하는가를 되묻게 만든다. 아직 성역의 언덕에서 칼을 들고 있다면 성역의 경계에서 총을 들고 있는 AI에게 총구의 방향과 총을 쏘는 방법을 알려주면서 상상과 두려움이 만들어낸 소외된 진짜 현실의 극한으로 조금씩 수렴해갈 필요가 있다.
이번 글에서는 회사 내 DB 에이전트에서 사용하고 있는 MCP 서버와 트리 기반의 추론 탐색 오픈소스를 공유해보려고 한다.
먼저 아래 그림을 보자. 아래 그림은 회사에서 사용하고 있는 DB 도사라는 AI 에이전트의 아키텍처를 간략하게 그림으로 나타낸 것이다. 여러 컴포넌트 중에 db-perf-mcp와 PageIndex라는 것이 보이는데, 이 2개 컴포넌트가 오늘 공유할 MCP 서버와 트리 기반의 추론 탐색 오픈소스이다.
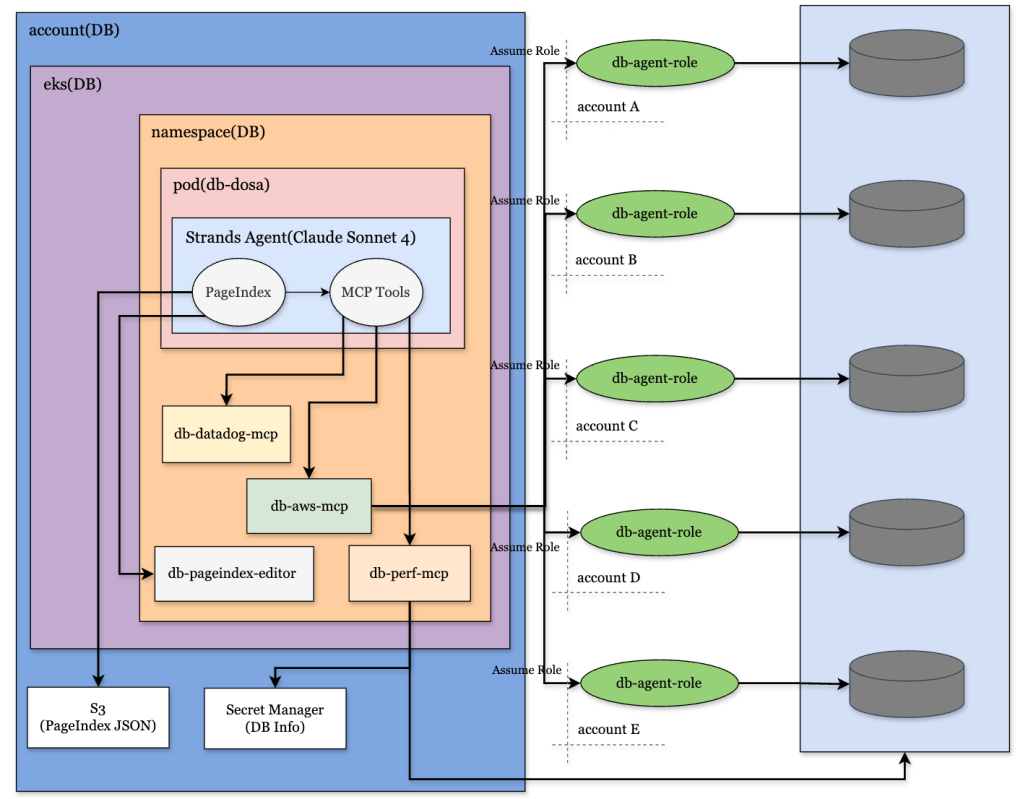
DB 도사 에이전트는 MCP 서버와 PageIndex를 다음과 같이 사용하고 있다.
- DB AWS MCP
- CloudWatch 메트릭 조회
- Performance Insights 조회
- 슬로우 & 에러 로그 조회
- Health Event 체크
- 관리 대상 리소스에 대한 액세스(Aurora MySQL/PostgreSQL, Oracle, ElastiCache, OpenSearch, MSK, MQ, Support)
- DB Perf MCP
- Real-Time DB 성능 모니터링(테이블 통계, 쿼리 실행계획, 잠금, 롱트랜잭션, 커넥션 등)
- DB Datadog MCP
- Downtime 설정
- 대시보드 설정
- 구 메트릭 조회
- PageIndex
- DB 서버 작업 히스토리 관리
- DB 서버별 특성 관리
- DB 부하 분석 토큰 조절
- LLM 행동 결정
이 중 AWS MCP 서버와 Datadog MCP 서버는 많이 사용하고 있을 것이다. 그리고 이것만으로도 꽤 유용한 정보들을 얻을 수 있다.
(물론 Datadog MCP는 서버 호스팅 문제로 직접 Datadog MCP를 개발해서 사용하고 있다.)
하지만 AWS와 Datadog MCP는 다음과 같은 정보들을 사용자에게 알려주지 않는다.
- DB 서버의 Real-Time 데이터
- 쿼리 실행 계획
- DB 모니터링 조회(잠금, 롱트랜잭션, 커넥션 상세 등)
- DB 서버 히스토리
- DB 서버 도메인 특성
- …
AWS의 database insights advanced와 Datadog의 DBM은 쿼리 실행 계획을 지원하기도 하지만 당연히 쓸만하지 않다. 특히나 Datadog DBM의 쿼리들은 API로 조회할 수 없고 반드시 데이터독 콘솔에 접속해야만 조회가 가능하다.
그럼 이제 본격적으로 DB Perf MCP와 PageIndex에 대해서 살펴보도록 하겠다.
DB Perf MCP
DB Perf MCP 서버는 이름 그대로 DB 성능 모니터링을 위해 만든 MCP 서버이다. Realtime으로 DB 서버의 상태를 확인할 수 있고 누구나 쉽게 필요한 성능 조회 쿼리 도구를 추가할 수 있다. 이 MCP 서버는 사실 Google의 genai-toolbox라는 오픈소스에서 아이디어를 얻었다. MCP Tool Box라고도 불리는데 일반적으로 많이 사용하는 MySQL과 PostgreSQL 외에도 여러 데이터베이스의 MCP Tool을 지원한다. 그대로 사용할 수는 없고 본인의 환경에 맞게 소스를 수정해서 사용하면 된다. 나의 경우 MySQL과 PostgreSQL Tools를 떼어다가 go언어로 작성되어 있던 코드를 파이썬으로 변환하고 툴에 사용되는 쿼리를 조금 수정해서 사용하고 있다.
위에 공유한 DB Perf MCP 서버에는 다음의 도구들이 등록되어 있다.
| DBMS | 도구명 | 기능 |
|---|---|---|
| MySQL | mysql_execute_sql | LLM이 생성한 SQL을 실행 (5초 타임아웃 제한) |
| mysql_list_active_queries | 실행 중인 쿼리 목록 | |
| mysql_list_table_fragmentation | 테이블 단편화 조회 | |
| mysql_list_tables_missing_unique_indexes | 유니크 인덱스 누락 테이블 | |
| list_databases | 전체 DB 목록 | |
| mysql_list_table_stats | 테이블 통계 (행수, 크기, 엔진) | |
| mysql_get_query_plan | EXPLAIN JSON 실행 계획 | |
| mysql_list_table_columns | 테이블 컬럼 정보 | |
| mysql_list_index_stats | 인덱스 사용 통계 | |
| mysql_list_locks | 락 대기 목록 | |
| mysql_list_connections | 커넥션 요약 (유저/호스트/DB별) | |
| mysql_list_global_variables | 글로벌 변수 조회 | |
| PostgreSQL | pg_execute_sql | LLM이 생성한 SQL을 실행 (5초 타임아웃 제한) |
| list_databases | 전체 DB 목록 | |
| pg_database_overview | 서버 개요 (버전, 복제 상태, 업타임, 커넥션) | |
| pg_list_active_queries | 실행 중인 쿼리 목록 | |
| pg_list_locks | 현재 락 목록 | |
| pg_replication_stats | 복제 지연 통계 | |
| pg_list_database_stats | 데이터베이스별 성능 통계 | |
| pg_list_logical_databases | 논리 데이터베이스 목록 (이름, 소유자, 크기) | |
| pg_list_roles | 사용자 역할 목록 | |
| pg_list_tablespaces | 테이블스페이스 목록 | |
| pg_list_pg_settings | PostgreSQL 설정값 조회 | |
| pg_long_running_transactions | 장기 실행 트랜잭션 | |
| pg_list_schemas | 스키마 목록 | |
| pg_list_tables | 테이블 목록 (소유자, 추정 행수, 크기) | |
| pg_list_table_stats | 테이블별 성능 통계 | |
| pg_list_table_columns | 테이블 컬럼 정보 | |
| pg_list_indexes | 인덱스 목록 (미사용 필터 지원) | |
| pg_list_sequences | 시퀀스 목록 | |
| pg_list_views | 뷰 목록 | |
| pg_list_triggers | 트리거 목록 | |
| pg_list_installed_extensions | 설치된 확장 목록 | |
| pg_list_available_extensions | 설치 가능한 확장 목록 | |
| pg_list_query_stats | pg_stat_statements 쿼리 통계 | |
| pg_list_publication_tables | 논리 복제 퍼블리케이션 테이블 | |
| pg_get_column_cardinality | 컬럼 카디널리티 추정 | |
| pg_list_stored_procedures | 저장 프로시저 목록 |
지원되는 도구들 중에 mysql_execute_sql과 pg_execute_sql은 사용자가 요청한 내용이 tool list에 없으면 호출되는 도구이다. 즉 LLM이 사용자 요청에 맞게 SQL문을 직접 작성하여 쿼리를 실행한다. 최초에는 LLM이 테이블 크기, 리소스 사용량 등을 고려하지 않고 본인이 생성한 쿼리를 그대로 수행하는 문제가 있었는데, 아예 이 2개 도구는 5초 타임아웃을 걸어놓고 그 이상 수행되면 종료되도록 만들었다.
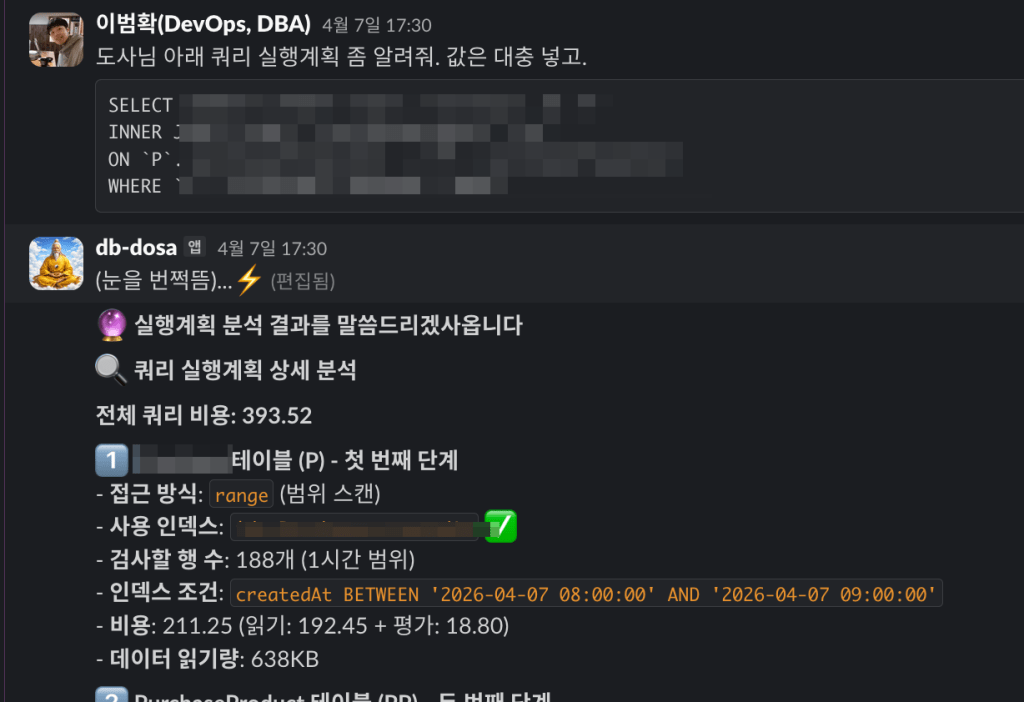
DBA마다 사용하는 모니터링 쿼리가 다를텐데 이 쿼리문을 MCP 도구로 등록하는 방법은 간단하다. src/queries/mysql.py 파일에서 아래처럼 모니터링 쿼리를 변수에 담아두고,
LIST_INDEX_STATS = """
SELECT
s.table_schema,
s.table_name,
s.index_name,
s.non_unique,
GROUP_CONCAT(s.column_name ORDER BY s.seq_in_index) AS columns,
s.index_type,
t.rows_read,
CASE WHEN t.rows_read IS NULL OR t.rows_read = 0 THEN 'UNUSED' ELSE 'USED' END AS usage_status
FROM information_schema.statistics s
LEFT JOIN sys.schema_index_statistics t
ON s.table_schema = t.table_schema
AND s.table_name = t.table_name
AND s.index_name = t.index_name
WHERE s.table_schema NOT IN ('sys', 'performance_schema', 'mysql', 'information_schema')
AND (COALESCE(%s, '') = '' OR s.table_schema = %s)
AND (COALESCE(%s, '') = '' OR s.table_name = %s)
GROUP BY s.table_schema, s.table_name, s.index_name, s.non_unique, s.index_type, t.rows_read
ORDER BY t.rows_read ASC, s.table_schema, s.table_name, s.index_name
LIMIT %s;
"""
src/tools/mysql.py 파일에서 함수를 작성하고 데코레이터만 달아주면 된다.
@mcp.tool()
@log_tool_call
async def mysql_list_index_stats(
db_name: str, table_schema: str = "", table_name: str = "", limit: int = 50,
) -> str:
"""List index usage statistics for MySQL. Shows which indexes are used or unused."""
return await mysql_query(db_name, my_q.LIST_INDEX_STATS,
(table_schema, table_schema, table_name, table_name, limit))
여담으로 MCP 서버들의 시스템 프롬프트는 컨텍스트 효율화를 위해 사용자 요청에 따라 카테고리 의존성 관계를 갖도록 설계되어 있다. 이 DB Perf MCP 서버는 기본적으로 본인의 base + 의존성 (aws_base + rds) 프롬프트를 시스템 프롬프트로 사용한다.
(LLM 답변의 품질이 떨어진다는 생각이 들면 프롬프트 의존성 관계를 키워드 가중치로 변경하는 것을 생각해볼 수도 있다.)
...
PROMPT_CATEGORIES = [
...
PromptCategory(
name="db_perf",
keywords=[
"db-perf", "perf", "성능", "performance",
"active query", "실행 중인 쿼리", "액티브 쿼리",
"lock", "락", "잠금", "데드락", "deadlock",
"replication", "복제", "지연", "lag",
"table stat", "테이블 통계", "테이블 크기", "테이블 사이즈",
"query stat", "쿼리 통계", "슬로우 쿼리", "slow query",
"index", "인덱스", "미사용 인덱스", "unused index",
"fragmentation", "단편화",
"long running", "장기 실행", "장기 트랜잭션", "롱트랜잭션", "롱 트랜잭션",
"extension", "확장", "pg_setting", "설정",
"vacuum", "dead row", "dead tuple",
"explain", "실행 계획", "쿼리 플랜", "실행계획",
"db 직접", "db 조회", "db 접속",
],
file="perf/base.md",
dependencies=["aws_base", "rds"],
),
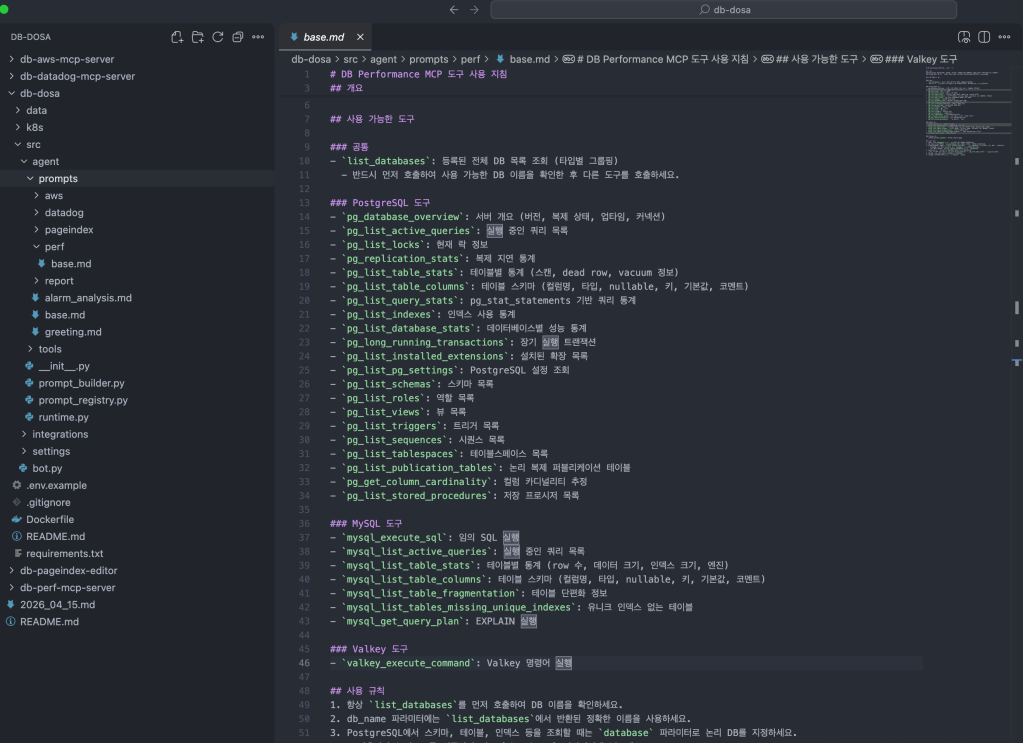
PageIndex 검색
벡터 검색은 쿼리와 문서 청크 간의 코사인 유사도 같은 수치적 거리를 기반으로 요청 내용을 검색한다. 하지만 검색하려는 단어와 의미적으로 가까운 청크를 반환하기 때문에 정작 필요한 데이터가 다른 곳에 있을 수 있다. 모든 엔지니어링이 그렇겠지만 데이터베이스 또한 유사도 기반으로 관련성 있는 문서를 검색하면 큰 낭패를 볼 수 있다. 좀 더 정확하고 전문성 있는 답변을 기대하는데 엉뚱한 문서를 참조해서 LLM이 답변을 작성한다면 그리고 그것을 실무에 적용한다면 DB 장애를 면치 못하게 될 것이다.
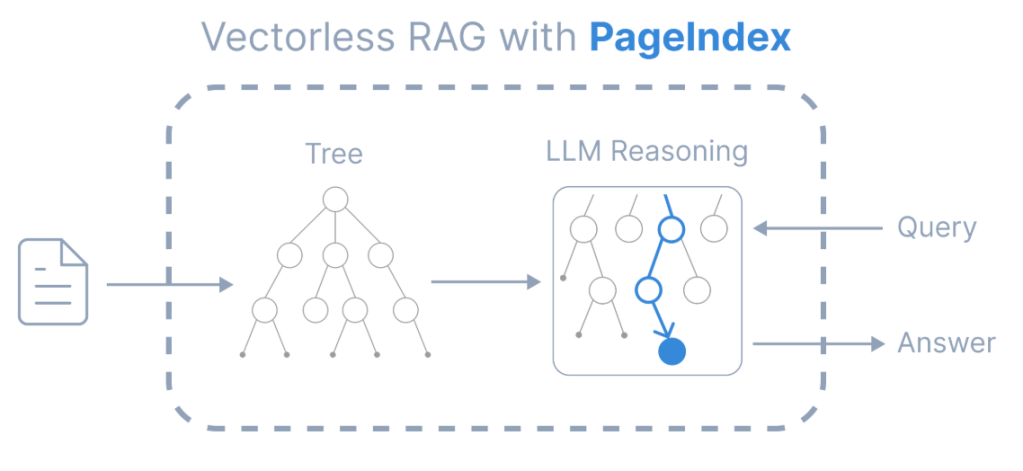
PageIndex는 이러한 유사도(similarity)와 관련성(relevance)의 관계를 부정하고 LLM을 사용하여 사용자 요청과 문서간의 관계를 트리 구조 기반으로 추론해서 검색한다.
벡터 검색이 모든 청크를 한꺼번에 비교해서 가장 가까운 걸 뽑는 “brute-force 유사도 매칭”이라면, PageIndex는 AlphaGo의 트리 탐색에서 영감을 받은 “top-down 추론 탐색” 인 것이다.
예를 들어, “어제 새벽 3시에 발생한 test DB 서버의 CPU 알람 원인 좀 확인해줘” 라는 질문에 대해 다음과 같이 동작한다.
- ① 프롬프트에 포함된 문서 목록에서 “test DB 서버” 문서 발견
- ② 목차 조회 → summary에 “새벽 2~4시 배치로 CPU 급증, 대응 불필요” 확인
- ③ 해당 페이지 내용 조회 → 상세 내용 확인
이 과정을 좀 더 상세히 살펴보면 아래 그림과 같다.
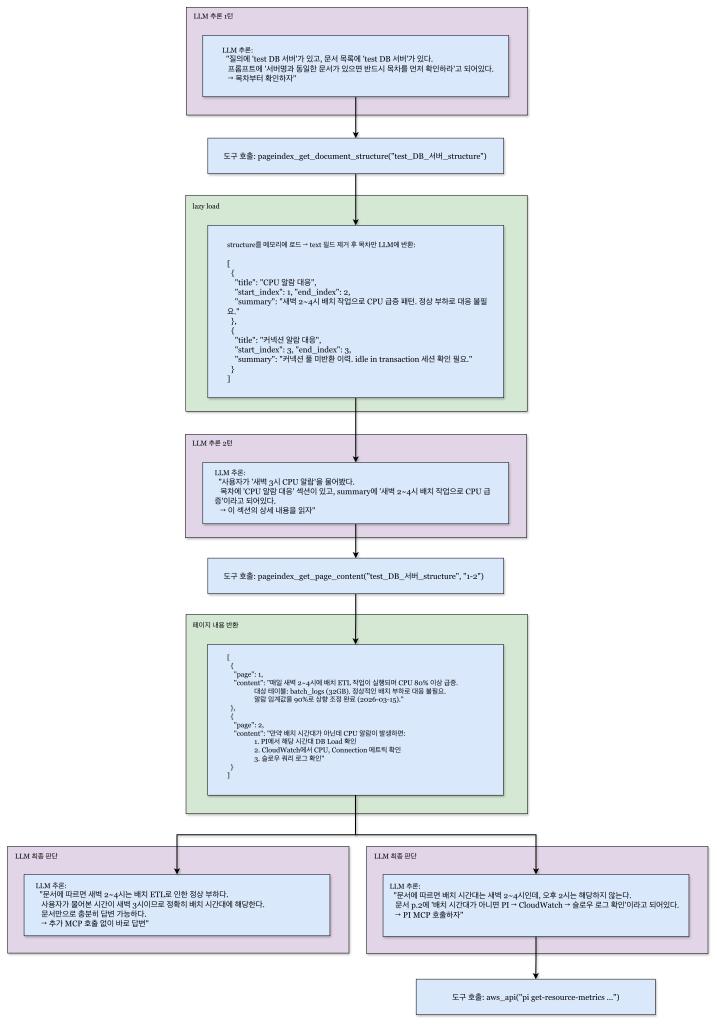
미리 저장해둔 문서 목록에서 사용자 요청과 관련 있는 문서를 찾고, 다시 사용자 요청과 관련있는 문서의 목차를 찾고, LLM의 추론 판단하에 해당 목차를 읽어야겠다는 판단이 들면 그제서야 해당 섹션의 전체 내용(contents)을 읽는다.
사람이 전문 서적을 참고하는 방법처럼 필요한 부분만 읽는 것이다.
test DB 서버 문서
├── 1장: CPU 알람 대응 (p.1-2)
│ ├── 1.1 배치 시간대 (p.1, summary: "새벽 2~4시 ETL 배치로 CPU 급증, 정상 부하")
│ └── 1.2 비배치 시간대 (p.2, summary: "PI → CloudWatch → 슬로우 로그 순서로 확인")
├── 2장: 커넥션 알람 대응 (p.3)
│ └── 2.1 커넥션 풀 이슈 (p.3, summary: "idle in transaction 세션 확인 필요")
└── 3장: 설정 변경 이력 (p.4-5)
├── 3.1 파라미터 변경 (p.4, summary: "2026-03 max_connections 200→300 변경")
└── 3.2 스펙 변경 (p.5, summary: "2026-02 db.r6g.large→xlarge 업그레이드")
그리고 마지막 추론 과정에서 LLM의 최종 판단하에 다음 행동을 결정짓는 것을 볼 수 있다. 더이상의 추가 정보는 불필요하다고 판단이 되면 추가적인 도구 호출 없이 답변을 종료한다. Agentic Loop를 문서의 내용에 따라 중간에 종료시킬 수 있는 것이다. 이는 LLM의 응답 속도를 줄일 수 있고, 토큰 사용량 또한 줄일 수 있는 방법이다.
LLM이 추론하는 JSON 파일의 구조는 아래와 같이 구조화되어 있다.

이 구조화된 JSON 데이터를 아래와 같은 순서로 처리하면서 필요한 페이지만 읽게 된다.
1. 트리 구조를 재귀적으로 평탄화해서 모든 노드를 리스트로 반환
@staticmethod
def _flatten_nodes(nodes: list) -> list:
result = []
for node in nodes:
result.append({k: v for k, v in node.items() if k != "nodes"})
if node.get("nodes"):
result.extend(PageIndexStore._flatten_nodes(node["nodes"]))
return result
2. 평탄화된 노드의 start_index~end_index 범위로 페이지별 텍스트를 조합
@staticmethod
def _build_pages(structure: list) -> List[dict]:
pages: Dict[int, str] = {}
for node in PageIndexStore._flatten_nodes(structure):
text = node.get("text", "")
if not text:
continue
for p in range(node.get("start_index", 0), node.get("end_index", 0) + 1):
if p not in pages:
pages[p] = text
else:
pages[p] += "\n\n" + text
return [{"page": p, "content": c} for p, c in sorted(pages.items())]
3. 목차 조회 시 text 필드를 재귀적으로 제거 (토큰 절약)
@staticmethod
def _remove_text_fields(data):
if isinstance(data, list):
return [PageIndexStore._remove_text_fields(item) for item in data]
if isinstance(data, dict):
return {
k: PageIndexStore._remove_text_fields(v) if k == "nodes" else v
for k, v in data.items()
if k != "text"
}
return data
4. “5-7,3,12” 같은 문자열을 [3, 5, 6, 7, 12]로 파싱
@staticmethod
def _parse_pages(pages_str: str) -> List[int]:
result = []
for part in pages_str.split(","):
part = part.strip()
if "-" in part:
start, end = part.split("-", 1)
result.extend(range(int(start.strip()), int(end.strip()) + 1))
else:
result.append(int(part))
return sorted(set(result))
5. pageindex_get_page_content 도구가 호출되면 메모리에 있는 doc[“pages”]에서 해당 페이지만 꺼내서 반환
@tool
def pageindex_get_page_content(doc_id: str, pages: str) -> str:
"""문서의 특정 페이지 내용을 조회합니다.
Args:
doc_id: 문서 ID
pages: 페이지 범위. 예: '5-7', '3,8', '12'
"""
store = get_store()
store.ensure_doc_loaded(doc_id)
doc = store.documents.get(doc_id)
if not doc or doc.get("pages") is None:
logger.warning("PageIndex 문서 없음: %s", doc_id)
return json.dumps({"error": f"문서를 찾을 수 없습니다: {doc_id}"}, ensure_ascii=False)
try:
page_nums = PageIndexStore._parse_pages(pages)
except (ValueError, AttributeError):
return json.dumps({"error": f"잘못된 페이지 형식: {pages}"}, ensure_ascii=False)
page_map = {p["page"]: p["content"] for p in doc.get("pages", [])}
result = [{"page": p, "content": page_map[p]} for p in page_nums if p in page_map]
preview = result[0]["content"][:100] if result else "(내용 없음)"
logger.info(
"PageIndex 페이지 조회: %s p.%s (%d페이지 반환)\n 내용 미리보기: %s...",
doc["doc_name"], pages, len(result), preview,
)
return json.dumps(result, ensure_ascii=False)
추가로, PageIndex의 원본 소스에서는 PDF 파일을 JSON 파일로 변환시켜주는 기능을 제공하고 있다.
(JSON 파일로의 변환은 LLM이 담당하기 때문에 토큰을 소비하게 된다. 문서의 내용이 방대할수록 문서 요약에 사용되는 토큰 수가 기하급수적으로 늘어날 수 있다.)
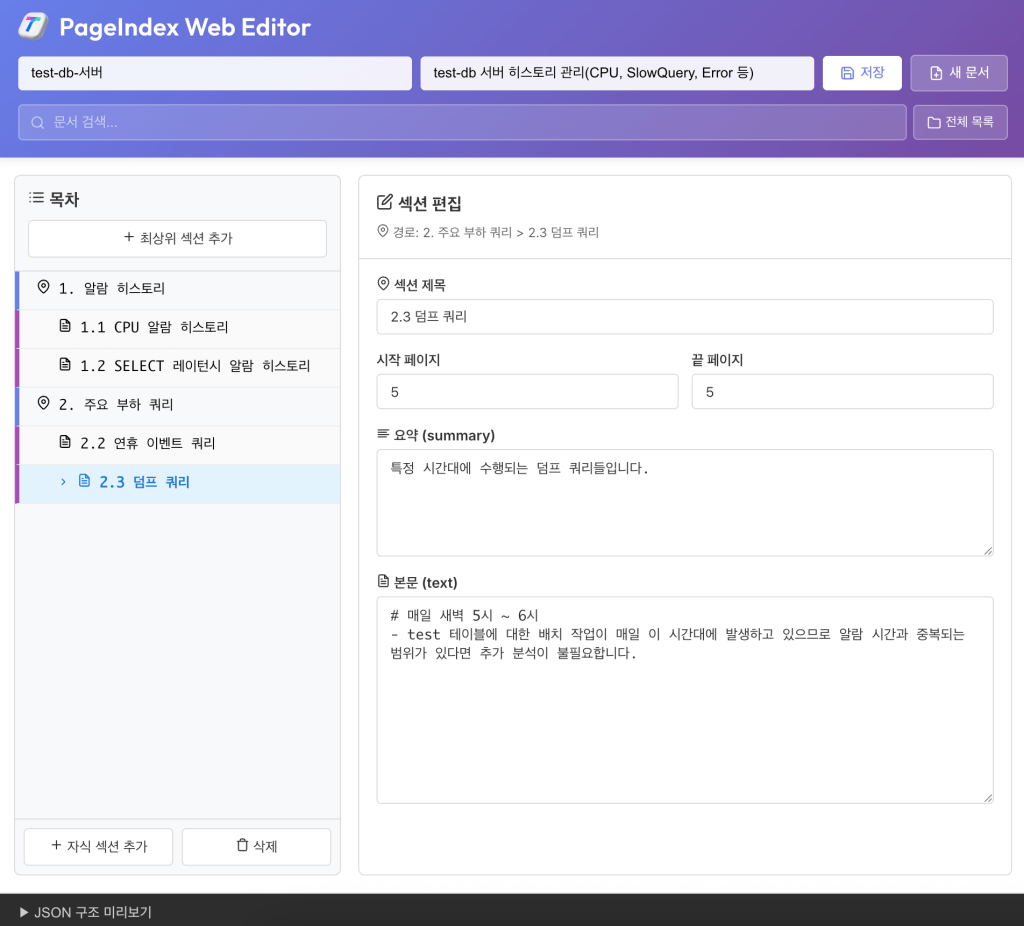
하지만 나는 PageIndex가 JSON 파일로 변환해주는 것도 싫고, json 데이터를 입력하는 것도 싫어서 메모장 쓰듯이 입력할 수 있는 별도의 웹페이지를 만들어서 사용하고 있다. 아래와 같이 웹 페이지에서 데이터를 입력하면 위에 첨부한 JSON 구조 형태로 파일이 저장된다.

대 AI시대 .. 난 또 무엇을 해야하나 머리를 열심히 굴려본다..

댓글 남기기